S3 Architecture Deep Dive
Ghi chú: Trong quá trình tìm hiểu về S3 storage, tôi tình cờ đọc được bài viết này: AWS S3 Deep Dive của Joud Wawad trên Medium. Bài viết rất chi tiết và chất lượng nên tôi lưu lại trên blog để tham khảo.
Amazon Simple Storage Service (Amazon S3) là một dịch vụ lưu trữ đối tượng (object storage) cung cấp khả năng mở rộng, tính sẵn sàng dữ liệu, bảo mật và hiệu suất hàng đầu trong ngành. Các công ty thuộc mọi quy mô và lĩnh vực đều có thể sử dụng Amazon S3 để lưu trữ và bảo vệ bất kỳ lượng dữ liệu nào cho nhiều use case khác nhau, chẳng hạn như data lakes, websites, ứng dụng di động, backup và restore, lưu trữ dài hạn (archive), ứng dụng doanh nghiệp, thiết bị IoT và phân tích dữ liệu lớn. Amazon S3 cung cấp các tính năng quản lý giúp bạn tối ưu hóa, tổ chức và cấu hình quyền truy cập dữ liệu để đáp ứng các yêu cầu cụ thể về kinh doanh, tổ chức và tuân thủ.
Ở mức tổng quan, các hệ thống lưu trữ được chia thành ba loại chính:
- Block storage
- File storage
- Object storage
Block storage
Block storage ra đời đầu tiên, vào những năm 1960. Các thiết bị lưu trữ phổ biến như ổ cứng HDD (Hard Disk Drive) và ổ SSD (Solid-State Drive) được gắn trực tiếp vào server đều được coi là block storage.
Block storage cung cấp các block dữ liệu thô cho server dưới dạng một volume (phân vùng lưu trữ). Đây là hình thức lưu trữ linh hoạt và đa năng nhất. Server có thể format các block thô này và sử dụng chúng như một file system, hoặc có thể giao quyền kiểm soát các block đó cho một ứng dụng. Một số ứng dụng như database hoặc virtual machine engine quản lý trực tiếp các block này để tận dụng tối đa hiệu suất.
Block storage không chỉ giới hạn ở lưu trữ gắn trực tiếp vào máy. Block storage có thể được kết nối với server qua mạng tốc độ cao hoặc qua các giao thức kết nối tiêu chuẩn như Fibre Channel (FC) và iSCSI. Về mặt khái niệm, block storage kết nối qua mạng vẫn cung cấp các block thô. Đối với server, nó hoạt động giống hệt như block storage gắn trực tiếp.
File storage
File storage được xây dựng trên nền tảng block storage. Nó cung cấp một lớp trừu tượng cấp cao hơn giúp việc xử lý file và thư mục dễ dàng hơn. Dữ liệu được lưu trữ dưới dạng file trong cấu trúc thư mục phân cấp (hierarchical directory structure). File storage là giải pháp lưu trữ đa năng phổ biến nhất. File storage có thể được truy cập bởi nhiều server thông qua các giao thức mạng cấp file như SMB/CIFS và NFS. Các server truy cập file storage không cần xử lý sự phức tạp của việc quản lý block, format volume, v.v. Sự đơn giản của file storage khiến nó trở thành giải pháp tuyệt vời để chia sẻ số lượng lớn file và thư mục trong một tổ chức.
Object storage
Object storage là loại mới nhất. Nó đánh đổi hiệu suất một cách có chủ đích để đạt được độ bền dữ liệu (durability) cao, quy mô khổng lồ và chi phí thấp. Nó nhắm vào dữ liệu tương đối “lạnh” (ít truy cập) và chủ yếu được dùng cho lưu trữ dài hạn (archival) và backup. Object storage lưu trữ tất cả dữ liệu dưới dạng object trong cấu trúc phẳng (flat structure). Không có cấu trúc thư mục phân cấp. Truy cập dữ liệu thường được cung cấp qua RESTful API. Nó tương đối chậm so với các loại lưu trữ khác. Hầu hết các nhà cung cấp dịch vụ đám mây công cộng đều có dịch vụ object storage, chẳng hạn như AWS S3, Google Object Storage và Azure Blob Storage.
How Amazon S3 works
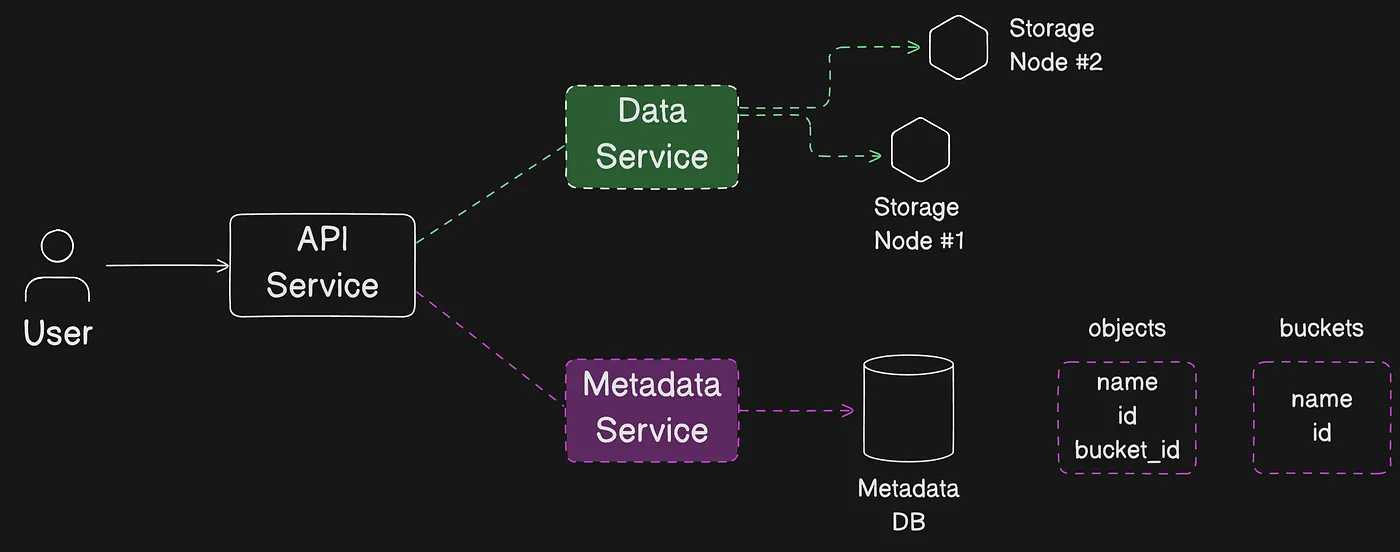
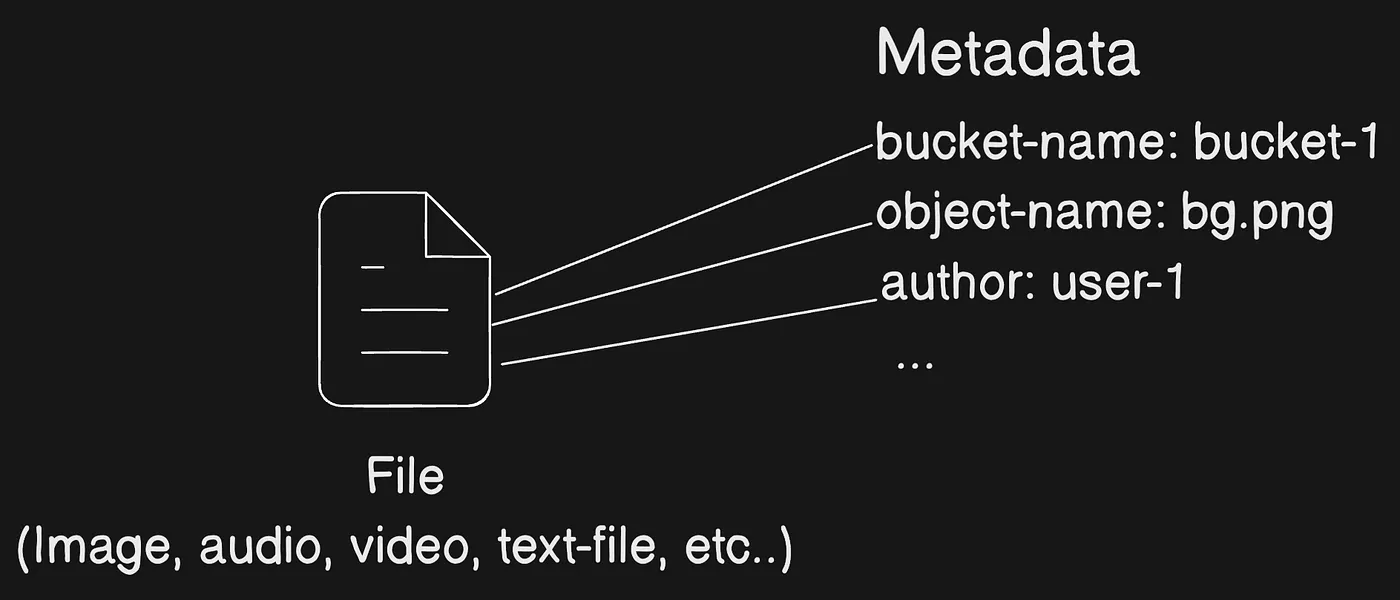
Amazon S3 là một dịch vụ object storage lưu trữ dữ liệu dưới dạng các object bên trong các bucket (thùng chứa). Một object là một file cùng với metadata mô tả file đó. Một bucket là một container chứa các object.
Để lưu trữ dữ liệu trong Amazon S3, trước tiên bạn tạo một bucket và chỉ định tên bucket cùng AWS Region. Sau đó, bạn upload dữ liệu vào bucket đó dưới dạng các object trong Amazon S3. Mỗi object có một key (hay key name), là định danh duy nhất cho object trong bucket.
S3 cung cấp các tính năng mà bạn có thể cấu hình để hỗ trợ use case cụ thể. Ví dụ, bạn có thể sử dụng S3 Versioning để giữ nhiều phiên bản của một object trong cùng một bucket, cho phép bạn khôi phục các object bị xóa hoặc ghi đè do nhầm lẫn.
Các bucket và object bên trong chúng mặc định là private và chỉ có thể truy cập khi bạn cấp quyền một cách rõ ràng. Bạn có thể sử dụng bucket policies, AWS Identity and Access Management (IAM) policies, access control lists (ACLs) và S3 Access Points để quản lý quyền truy cập.
 Cách S3 lưu object vào bucket và phân quyền truy cập
Cách S3 lưu object vào bucket và phân quyền truy cập
Để hiểu đầy đủ về S3, chúng ta cần tập trung vào hai chủ đề chính:
- Buckets
- Objects
Sau đó, chúng ta sẽ tìm hiểu các chiến lược khác nhau trong S3 để quản lý các bucket và object này:
- Data Encryption
- Data Protection
- Optimizing Performance
S3 Buckets
Để lưu trữ dữ liệu trong Amazon S3, bạn làm việc với các tài nguyên được gọi là bucket và object. Một bucket là container chứa các object. Một object là một file cùng với metadata mô tả file đó.
 Một object gồm file dữ liệu kèm metadata mô tả
Một object gồm file dữ liệu kèm metadata mô tả
Để lưu trữ một object trong Amazon S3, bạn tạo một bucket rồi upload object vào bucket đó. Khi object đã ở trong bucket, bạn có thể mở, tải xuống và di chuyển nó. Khi không còn cần object hoặc bucket nữa, bạn có thể dọn dẹp tài nguyên.
AWS S3 hỗ trợ ba loại bucket mà chúng ta sẽ thảo luận chi tiết: General-purpose buckets, Directory buckets, và Table buckets.
- General purpose buckets là loại bucket S3 gốc và được khuyến nghị cho hầu hết use case và access pattern. General purpose buckets cũng cho phép object được lưu trữ trên tất cả các storage class, ngoại trừ S3 Express One Zone.
- Directory buckets sử dụng storage class S3 Express One Zone, được khuyến nghị nếu ứng dụng của bạn nhạy cảm về hiệu suất và cần độ trễ
PUTvàGETở mức mili giây đơn (single-digit millisecond). - Table buckets — Amazon S3 Tables cung cấp lưu trữ S3 được tối ưu cho các workload phân tích (analytics), với các tính năng được thiết kế để liên tục cải thiện hiệu suất truy vấn và giảm chi phí lưu trữ cho các bảng dữ liệu (table). S3 Tables được xây dựng chuyên biệt cho việc lưu trữ dữ liệu dạng bảng (tabular data), chẳng hạn như giao dịch mua hàng hàng ngày, dữ liệu sensor streaming hoặc lượt hiển thị quảng cáo (ad impression). Dữ liệu dạng bảng biểu diễn dữ liệu theo cột và hàng, giống như trong một bảng cơ sở dữ liệu.
Amazon S3 hỗ trợ global buckets, nghĩa là mỗi tên bucket phải là duy nhất trên tất cả các AWS account trong tất cả các AWS Region trong cùng một partition. Partition là một nhóm các Region. AWS hiện có ba partition: aws (Standard Regions), aws-cn (China Regions) và aws-us-gov (AWS GovCloud (US)).
Amazon S3 tạo bucket trong Region mà bạn chỉ định. Để giảm độ trễ, tối thiểu chi phí hoặc đáp ứng yêu cầu pháp lý, hãy chọn AWS Region gần vị trí địa lý của bạn nhất. Ví dụ, nếu bạn ở châu Âu, bạn có thể thấy thuận lợi khi tạo bucket tại Region Europe (Ireland) hoặc Europe (Frankfurt).
General Purpose Buckets
General-purpose bucket là container chứa các object được lưu trữ trong Amazon S3. Bạn có thể lưu trữ bất kỳ số lượng object nào trong một bucket và tất cả các account đều có quota mặc định là 10.000 general-purpose bucket.
Mỗi object đều nằm trong một bucket. Ví dụ, nếu object có tên photos/puppy.jpg được lưu trong bucket amzn-s3-demo-bucket ở Region US West (Oregon), thì nó có thể được truy cập qua URL [https://amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpg](https://amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpg.).
S3 General Purpose buckets sử dụng cái gọi là Flat Storage Structure (cấu trúc lưu trữ phẳng), nơi tất cả file được tổ chức ở cùng một cấp, không có thư mục hay thư mục con, tương tự như việc đặt tất cả tài liệu vào một thư mục duy nhất. Nó dựa vào metadata tags và unique identifiers để phân loại và truy xuất file, bù đắp cho việc thiếu cấu trúc thư mục lồng nhau.
+-------------------+
| Flat Storage |
+-------------------+
| File1 |
| File2 |
| File3 |
| ... |
| FileN |
+-------------------+Directory Buckets
Directory buckets hỗ trợ tạo bucket tại các loại vị trí sau: Availability Zone hoặc Local Zone.
Cho các use case cần độ trễ thấp, bạn có thể tạo directory bucket trong một Availability Zone duy nhất để lưu trữ dữ liệu. Directory buckets trong Availability Zones hỗ trợ storage class S3 Express One Zone. S3 Express One Zone được khuyến nghị nếu ứng dụng của bạn nhạy cảm về hiệu suất và cần độ trễ PUT và GET ở mức mili giây đơn.
Directory buckets tổ chức dữ liệu theo cấu trúc phân cấp thành các thư mục (directory), khác với cấu trúc lưu trữ phẳng của general-purpose buckets. Không có giới hạn prefix cho directory buckets, và các thư mục riêng lẻ có thể mở rộng theo chiều ngang (scale horizontally).
+-------------------+
| Root Directory |
+-------------------+
|
+-- Folder1
| +-- Subfolder1
| | +-- File1
| | +-- File2
| +-- Subfolder2
| +-- File3
|
+-- Folder2
+-- File4
+-- File5Bạn có thể tạo tối đa 100 directory buckets trong mỗi AWS account, không giới hạn số lượng object có thể lưu trong một bucket. Quota bucket được áp dụng cho từng Region trong AWS account của bạn. Nếu ứng dụng cần tăng giới hạn này, hãy liên hệ AWS Support.
So sánh cấu trúc phẳng của general-purpose bucket với cấu trúc phân cấp của directory bucket
Directories
Directory buckets tổ chức dữ liệu theo cấu trúc phân cấp thành các thư mục, khác với cấu trúc sắp xếp phẳng của general purpose buckets.
Với hierarchical namespace (không gian tên phân cấp), delimiter (ký tự phân cách) trong object key rất quan trọng. Delimiter duy nhất được hỗ trợ là dấu gạch chéo (/). Các thư mục được xác định bởi ranh giới delimiter. Ví dụ, object key dir1/dir2/file1.txt sẽ tự động tạo các thư mục dir1/ và dir2/, và object file1.txt được thêm vào thư mục /dir2 theo đường dẫn dir1/dir2/file1.txt.
Mô hình indexing của directory bucket trả về kết quả không được sắp xếp cho API ListObjectsV2. Nếu bạn cần giới hạn kết quả vào một phần con của bucket, bạn có thể chỉ định đường dẫn thư mục con trong tham số prefix, ví dụ prefix=dir1/.
Key names
Đối với directory buckets, các thư mục con chung cho nhiều object key được tạo cùng với object key đầu tiên. Các object key bổ sung cho cùng thư mục con sẽ sử dụng thư mục con đã tạo trước đó. Mô hình này cho bạn sự linh hoạt trong việc chọn object key phù hợp nhất với ứng dụng, với hỗ trợ ngang nhau cho cả thư mục thưa (sparse) và thư mục dày (dense).
Use cases cho directory buckets
Cho các use case cần độ trễ thấp, bạn có thể tạo directory bucket trong một Availability Zone duy nhất để lưu trữ dữ liệu. Directory buckets trong Availability Zones hỗ trợ storage class S3 Express One Zone. S3 Express One Zone được khuyến nghị nếu ứng dụng của bạn nhạy cảm về hiệu suất và cần độ trễ PUT và GET ở mức mili giây đơn.
High-performance workloads
Amazon S3 Express One Zone là storage class hiệu suất cao, đơn zone, được thiết kế cho các ứng dụng nhạy cảm về độ trễ (latency-sensitive). Nó cung cấp tốc độ truy cập cao nhất có thể bằng cách đặt object storage cùng vị trí với tài nguyên compute trong cùng một Availability Zone.
Các lợi ích chính bao gồm:
- Low Latency: Cung cấp truy cập dữ liệu ở mức mili giây đơn, nhanh hơn S3 Standard tới 10 lần.
- Cost Efficiency: Chi phí request thấp hơn 50% so với S3 Standard.
- Performance Elasticity: Tương tự như các storage class S3 khác.
- Redundancy: Xử lý các sự cố thiết bị đồng thời bằng cách chuyển request sang thiết bị mới trong cùng Availability Zone.
Lý tưởng cho các ứng dụng yêu cầu độ trễ tối thiểu, chẳng hạn như:
- Human-Interactive Workflows: Chỉnh sửa video và các tác vụ sáng tạo khác.
- Analytics and Machine Learning: Các workload có truy cập dữ liệu thường xuyên hoặc ngẫu nhiên.
S3 Express One Zone có thể tích hợp với các dịch vụ AWS như Amazon EMR, Amazon SageMaker và Amazon Athena để hỗ trợ các workload analytics và AI/ML.
Để có hiệu suất tối ưu, hãy chỉ định AWS Region và Availability Zone gần với compute instance của bạn (ví dụ: Amazon EC2, Amazon EKS hoặc Amazon ECS). Bạn có thể truy cập S3 Express One Zone directory buckets từ VPC bằng gateway VPC endpoint, không cần internet gateway hay NAT device.
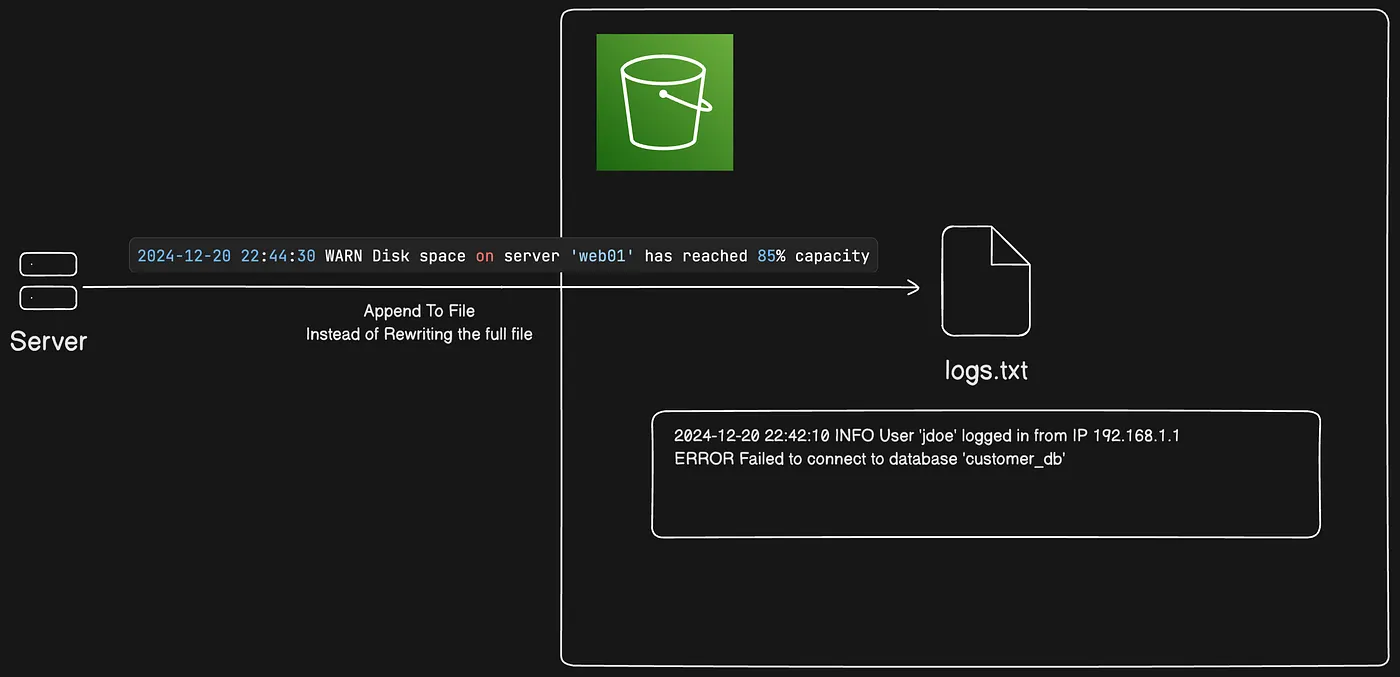
Thêm dữ liệu vào object trong directory buckets (Appending data)
Bạn có thể thêm dữ liệu (append) vào các object hiện có trong S3 Express One Zone directory buckets. Điều này hữu ích cho dữ liệu được ghi liên tục hoặc khi bạn cần đọc trong lúc ghi, chẳng hạn như thêm log entries hoặc video segments.
Các điểm chính:
- No Minimum Size: Thêm dữ liệu bất kỳ kích thước nào, tối đa 5GB mỗi request.
- Maximum Parts: Mỗi object có thể có tối đa 10.000 parts.
- Multipart Upload: Các part từ multipart upload được tính vào giới hạn 10.000 parts.
Nếu bạn đạt giới hạn, bạn sẽ nhận lỗi TooManyParts. Sử dụng API CopyObject để reset số lượng.
Để upload song song mà không cần đọc các part trong quá trình upload, hãy sử dụng Amazon S3 multipart upload.
 Thêm dữ liệu nối tiếp vào object trong S3 Express One Zone directory bucket
Thêm dữ liệu nối tiếp vào object trong S3 Express One Zone directory bucket
Append chỉ được hỗ trợ cho các object trong S3 Express One Zone directory buckets.
Session Based Authentication
Với regional buckets, mỗi request đều yêu cầu xác thực (authentication), cung cấp độ chi tiết cao (high granularity) và các policy biểu đạt mạnh mẽ trong IAM và bucket policies. Tuy nhiên, quá trình xác thực này gây ra một số độ trễ, tích lũy qua nhiều request.
Để giải quyết vấn đề này, AWS giới thiệu Create Session API mới cho directory buckets. API này cho phép người dùng xác thực một phiên (session) và phân bổ độ trễ xác thực liên quan qua các request tiếp theo bằng cách lấy một token cấp quyền truy cập toàn bộ bucket. Session có thể hoạt động ở ba chế độ: chỉ đọc (read-only), chỉ ghi (write-only) hoặc đọc-ghi (read-write), cung cấp các tùy chọn cần thiết cho người dùng.
Trong khi AWS trừu tượng hóa hầu hết các phức tạp về bảo mật trong SDK, việc viết bucket policies cho directory buckets khác biệt do cơ chế xác thực data path khác nhau. Đơn giản hóa policies cho directory buckets bao gồm các hành động như cho phép tạo session dựa trên các principal cụ thể.
Anti-patterns
Khi quyết định không sử dụng AWS Directory buckets, bạn cần xem xét các hạn chế cụ thể có thể cản trở việc hỗ trợ use case của bạn. Các ràng buộc này bao gồm:
- Các object trong Directory buckets không thể được gắn tag. Do đó, việc copy một object có tag vào Directory bucket sẽ trả về phản hồi 501 Not Implemented.
- Directory buckets trở nên inactive sau khi không có hoạt động request trong 3 tháng. Trong trạng thái inactive, bucket không thể truy cập cho cả đọc và ghi. Việc kích hoạt lại xảy ra khi có yêu cầu truy cập, có thể mất vài phút, dẫn đến phản hồi 503 slowdown cho các request đọc và ghi.
- Chỉ Server Side Encryption với S3 Managed keys (SSE-S3) được hỗ trợ cho Directory buckets. Các phương pháp mã hóa khác như SSE-KMS và SSE-C không tương thích.
- Nhiều tính năng S3 thiết yếu như Multi-Factor Authentication, S3 Versioning, Replication, Inventory reports và S3 event notifications không được hỗ trợ cùng với Directory buckets.
- Mô hình ủy quyền (authorization) khác biệt cho Directory buckets, không có ủy quyền cấp object; thay vào đó, ủy quyền phải được thực hiện ở cấp bucket.
S3 Table Buckets
Amazon S3 Tables cung cấp lưu trữ S3 được tối ưu cho các workload analytics, với các tính năng được thiết kế để liên tục cải thiện hiệu suất truy vấn và giảm chi phí lưu trữ cho bảng dữ liệu. S3 Tables được xây dựng chuyên biệt cho việc lưu trữ dữ liệu dạng bảng (tabular data), chẳng hạn như giao dịch mua hàng hàng ngày, dữ liệu sensor streaming hoặc lượt hiển thị quảng cáo. Dữ liệu dạng bảng biểu diễn dữ liệu theo cột và hàng, giống như trong một bảng cơ sở dữ liệu.
Dữ liệu trong S3 Tables được lưu trữ trong một loại bucket mới: table bucket, lưu trữ các table dưới dạng subresource. Table buckets hỗ trợ lưu trữ table ở định dạng Apache Iceberg. Sử dụng các câu lệnh SQL tiêu chuẩn, bạn có thể truy vấn table với các query engine hỗ trợ Iceberg, chẳng hạn như Amazon Athena, Amazon Redshift và Apache Spark.
Table buckets được dùng để lưu trữ dữ liệu dạng bảng và metadata dưới dạng object cho các workload analytics. Table buckets có thể so sánh với data warehouse trong analytics.
Tính năng của S3 Tables
S3 Tables đi kèm các tính năng sẵn có:
- Purpose-built storage for tables — Lưu trữ được xây dựng chuyên biệt cho bảng dữ liệu
- Built-in support for Apache Iceberg — Hỗ trợ sẵn Apache Iceberg
- Automated table optimization — Tối ưu hóa bảng tự động
- Access management and security — Quản lý truy cập và bảo mật
- Integration with AWS analytics services — Tích hợp với các dịch vụ analytics của AWS
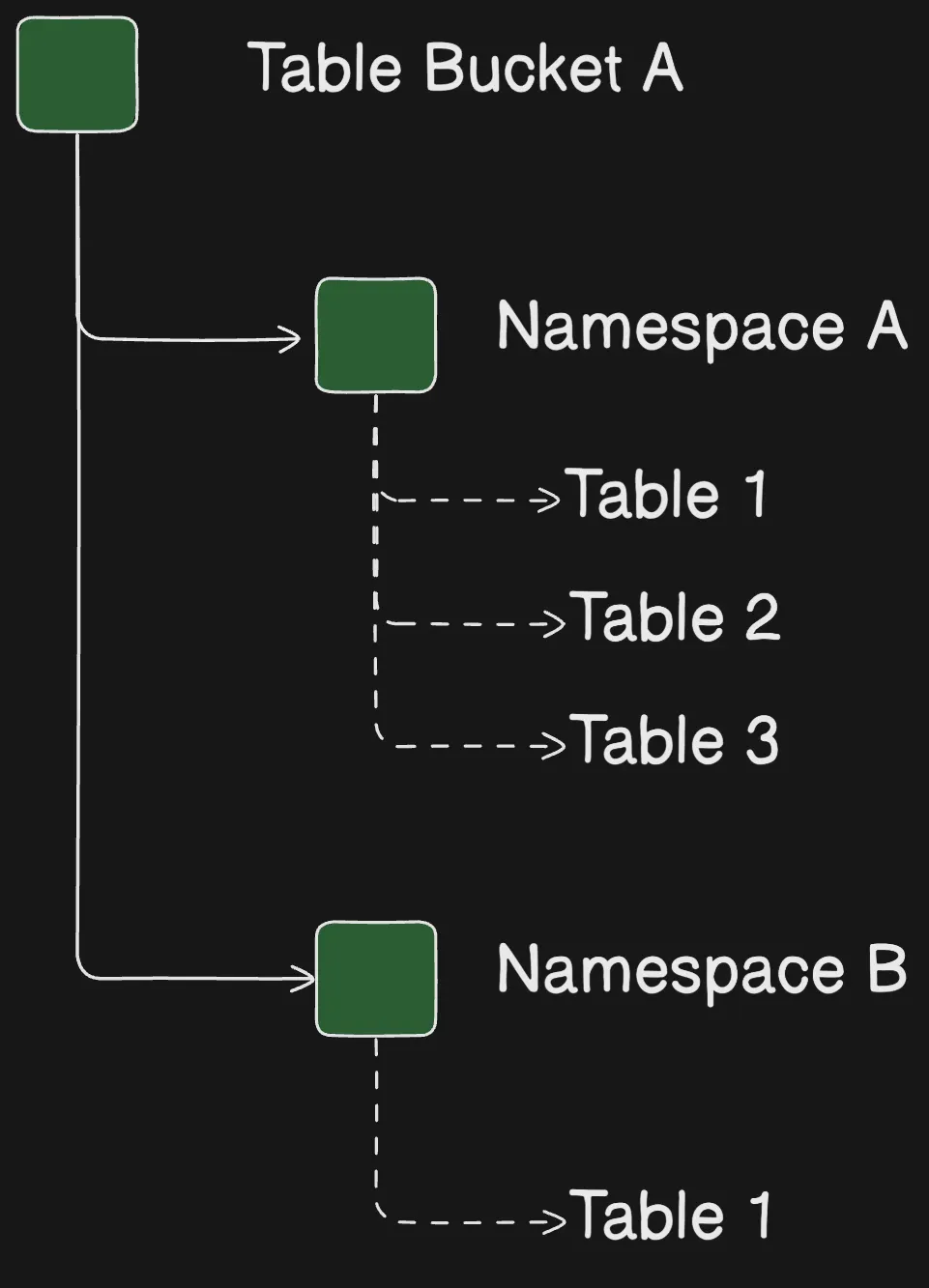
S3 Tables Namespaces
Khi bạn tạo table trong table bucket, bạn tổ chức chúng thành các nhóm logic gọi là namespace (không gian tên). Không giống S3 tables và Table buckets, namespace không phải là tài nguyên (resource), chúng là các cấu trúc giúp bạn tổ chức và quản lý table theo cách có thể mở rộng. Ví dụ, tất cả table thuộc phòng HR trong công ty có thể được nhóm dưới namespace hr.
Bạn có thể sử dụng table bucket resource policies để giới hạn quyền truy cập vào các namespace cụ thể.
 Cấu trúc table bucket gom các table theo namespace
Cấu trúc table bucket gom các table theo namespace
So sánh toàn diện các loại S3 Bucket
Với sự phức tạp và đa dạng của các loại S3 bucket, việc có một bảng so sánh toàn diện là cần thiết để hiểu rõ các use case cụ thể và tình huống sử dụng tối ưu. Bản tóm tắt này cung cấp phân tích chuyên sâu về các điểm khác biệt chính giữa các loại S3 bucket do AWS cung cấp, giúp bạn đưa ra quyết định sáng suốt về thời điểm và cách sử dụng từng loại bucket hiệu quả.
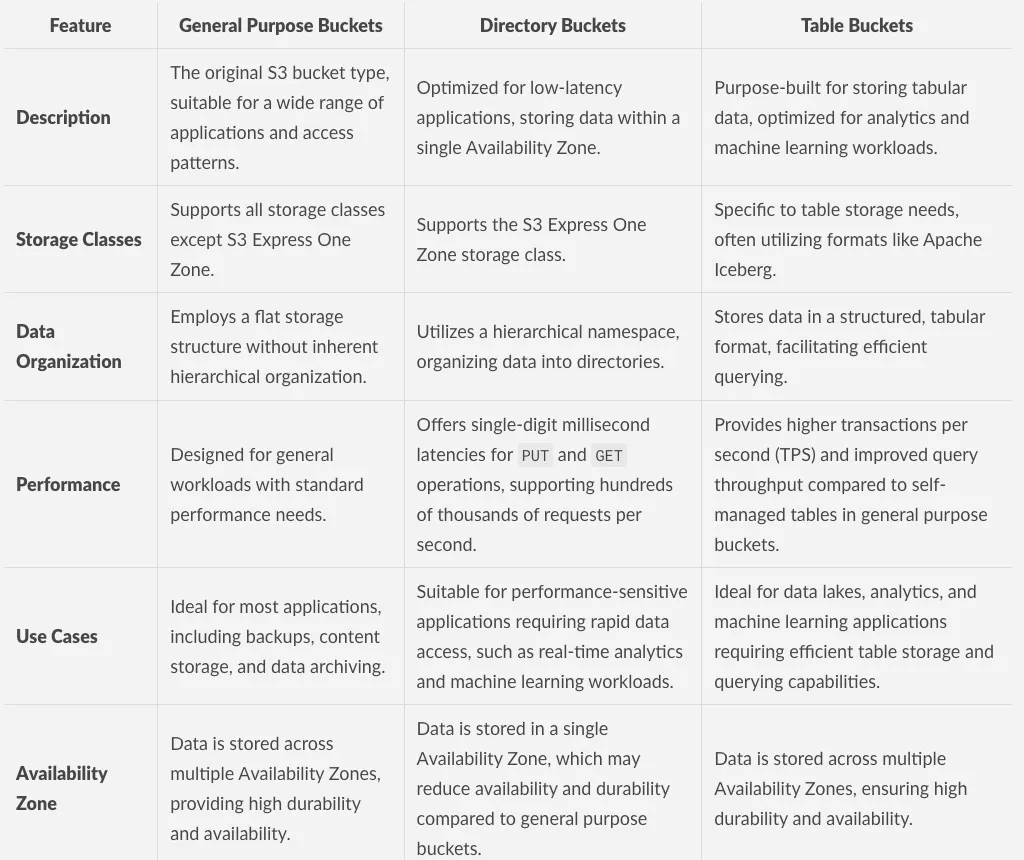 Bảng so sánh đặc điểm các loại S3 bucket, phần một
Bảng so sánh đặc điểm các loại S3 bucket, phần một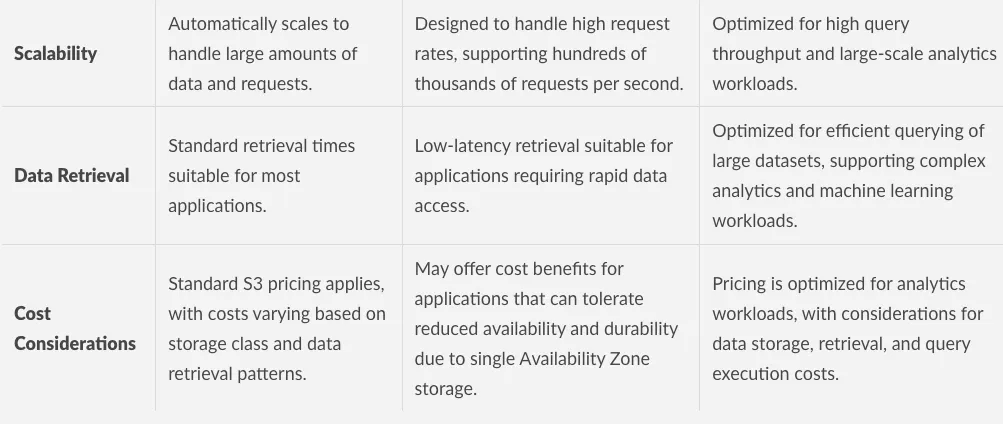 Bảng so sánh đặc điểm các loại S3 bucket, phần hai
Bảng so sánh đặc điểm các loại S3 bucket, phần hai
Objects trong S3
Để lưu trữ dữ liệu trong Amazon S3, bạn làm việc với các tài nguyên được gọi là bucket và object. Một bucket là container chứa các object. Một object là một file cùng với metadata mô tả file đó.
Để lưu trữ một object trong Amazon S3, bạn tạo một bucket rồi upload object vào bucket đó. Khi object đã ở trong bucket, bạn có thể mở, tải xuống và sao chép nó. Khi không còn cần object hoặc bucket nữa, bạn có thể dọn dẹp các tài nguyên này.
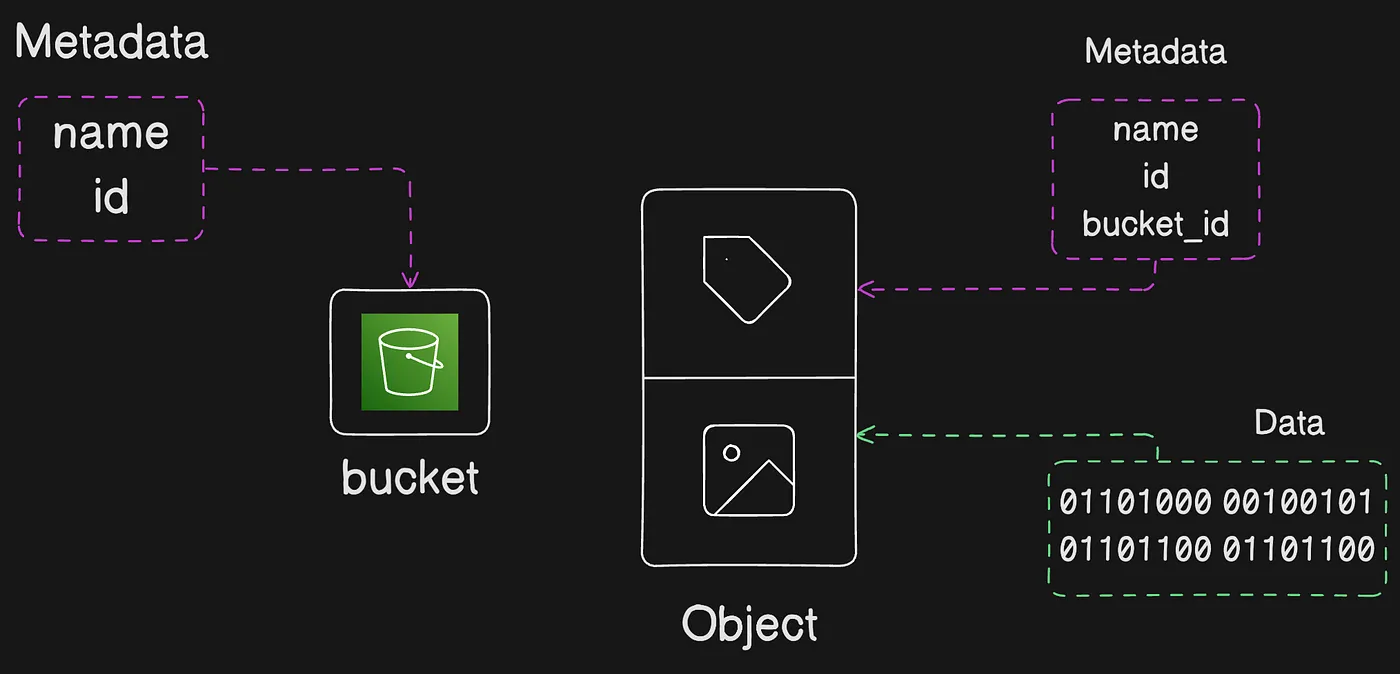 Cách các object được lưu trữ bên trong S3 bucket
Cách các object được lưu trữ bên trong S3 bucket
Tổng quan về Amazon S3 objects
Amazon S3 là một object store sử dụng key-value duy nhất để lưu trữ bao nhiêu object tùy ý. Bạn lưu các object này trong một hoặc nhiều bucket, và mỗi object có thể có kích thước lên tới 5 TB. Một object bao gồm các thành phần sau:
Key
Tên mà bạn gán cho object. Bạn sử dụng object key để truy xuất object.
Version ID
Trong một bucket, key và version ID xác định duy nhất một object. Version ID là chuỗi ký tự mà Amazon S3 tạo ra khi bạn thêm object vào bucket.
Value
Nội dung mà bạn đang lưu trữ.
Giá trị của object có thể là bất kỳ chuỗi byte nào. Object có thể có kích thước từ 0 đến 5 TB.
Metadata
Một tập hợp các cặp name-value cho phép bạn lưu thông tin liên quan đến object. Bạn có thể gán metadata, được gọi là user-defined metadata, cho các object trong Amazon S3. Amazon S3 cũng gán system-metadata cho các object này, được sử dụng để quản lý object.
Subresources
Amazon S3 sử dụng cơ chế subresource để lưu trữ thông tin bổ sung cho từng object. Vì subresource là phụ thuộc của object, chúng luôn được liên kết với một thực thể khác như object hoặc bucket.
Access control information
Bạn có thể kiểm soát quyền truy cập vào các object mà bạn lưu trữ trong Amazon S3. Amazon S3 hỗ trợ cả kiểm soát truy cập dựa trên tài nguyên (resource-based), chẳng hạn như access control list (ACL) và bucket policies, cũng như kiểm soát truy cập dựa trên người dùng (user-based).
Các tài nguyên Amazon S3 của bạn (ví dụ: bucket và object) mặc định là private. Bạn phải cấp quyền một cách rõ ràng để người khác truy cập các tài nguyên này.
Tags
Bạn có thể sử dụng tag để phân loại object đã lưu trữ, cho kiểm soát truy cập hoặc phân bổ chi phí (cost allocation).
Hãy cùng khám phá từng thuộc tính này chi tiết và sau đó nói về các hành động cụ thể liên quan đến object trong S3.
Object metadata
Có hai loại object metadata trong Amazon S3: system-defined metadata và user-defined metadata.
System-defined metadata bao gồm metadata như ngày tạo object, kích thước và storage class. User-defined metadata là metadata mà bạn có thể chọn thiết lập tại thời điểm upload object. User-defined metadata là một tập hợp các cặp name-value.
Khi bạn tạo object, bạn chỉ định object key (hay key name), xác định duy nhất object trong Amazon S3 bucket.
Sau khi upload object, bạn không thể sửa đổi user-defined metadata này. Cách duy nhất để sửa đổi metadata là tạo bản sao của object và thiết lập metadata mới.
Mặc định, S3 Metadata cung cấp system-defined object metadata, chẳng hạn như thời gian tạo object và storage class, cũng như custom metadata như tag và user-defined metadata được đính kèm khi upload object. S3 Metadata cũng cung cấp event metadata, chẳng hạn như khi object được cập nhật hoặc xóa, và AWS account đã thực hiện request.
Truy vấn metadata và tăng tốc khám phá dữ liệu với S3 Metadata (Tính năng đang ở chế độ Preview)
Amazon S3 Metadata tăng tốc khám phá dữ liệu bằng cách tự động thu thập metadata cho các object trong general purpose buckets của bạn và lưu trữ chúng trong các bảng Apache Iceberg chỉ đọc (read-only), được quản lý hoàn toàn, mà bạn có thể truy vấn. Các bảng chỉ đọc này được gọi là metadata tables. Khi object được thêm, cập nhật và xóa khỏi general purpose buckets, S3 Metadata tự động cập nhật các metadata table tương ứng để phản ánh các thay đổi mới nhất.
Với S3 Metadata, bạn có thể dễ dàng tìm, lưu trữ và truy vấn metadata cho các S3 object, giúp bạn nhanh chóng chuẩn bị dữ liệu cho business analytics, truy xuất nội dung, đào tạo mô hình AI/ML (trí tuệ nhân tạo/học máy) và nhiều hơn nữa.
Metadata tables được lưu trong S3 table buckets, cung cấp lưu trữ được tối ưu cho dữ liệu dạng bảng. Để dễ dàng truy vấn metadata, bạn có thể tích hợp table bucket với AWS Glue Data Catalog. Sau khi table bucket được tích hợp với AWS Glue Data Catalog, bạn có thể truy vấn trực tiếp metadata tables bằng các query engine như Amazon Athena, Amazon EMR, Amazon Redshift, Apache Spark và Apache Trino. Bạn cũng có thể truy vấn metadata tables bằng bất kỳ ứng dụng nào hỗ trợ định dạng Apache Iceberg. Để tạo dashboard từ metadata tables, sử dụng Amazon QuickSight.
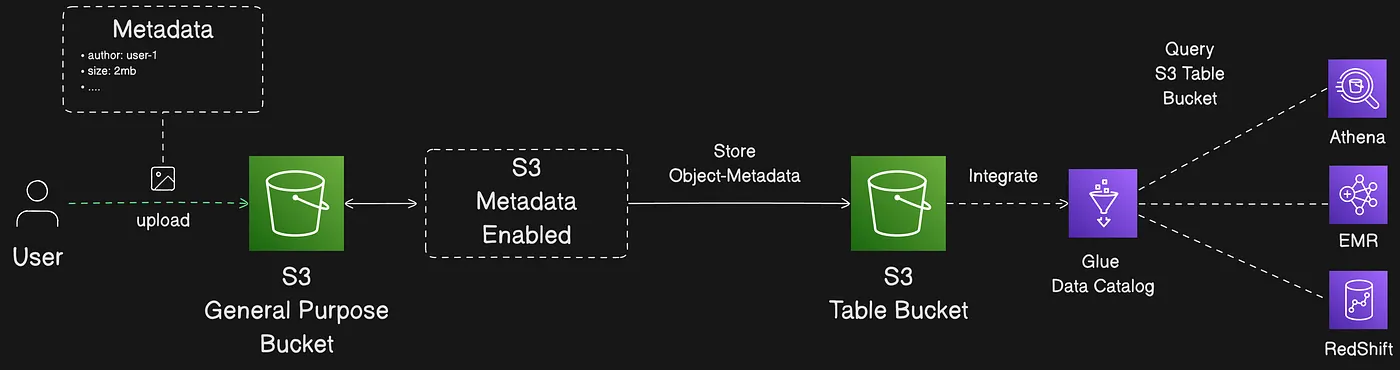 S3 Metadata tự thu thập metadata vào bảng Iceberg để truy vấn
S3 Metadata tự thu thập metadata vào bảng Iceberg để truy vấn
Uploading objects
Khi bạn upload một file lên Amazon S3, nó được lưu trữ dưới dạng S3 object. Object bao gồm dữ liệu file và metadata mô tả object. Bạn có thể có không giới hạn số lượng object trong một bucket. Trước khi upload file lên Amazon S3 bucket, bạn cần quyền ghi (write permission) cho bucket đó.
Nếu bạn upload object với key name đã tồn tại trong bucket có bật versioning, Amazon S3 sẽ tạo phiên bản mới của object thay vì ghi đè object hiện có.
Khi upload object, object được tự động mã hóa sử dụng server-side encryption với Amazon S3 managed keys (SSE-S3) theo mặc định. Khi tải xuống, object được giải mã.
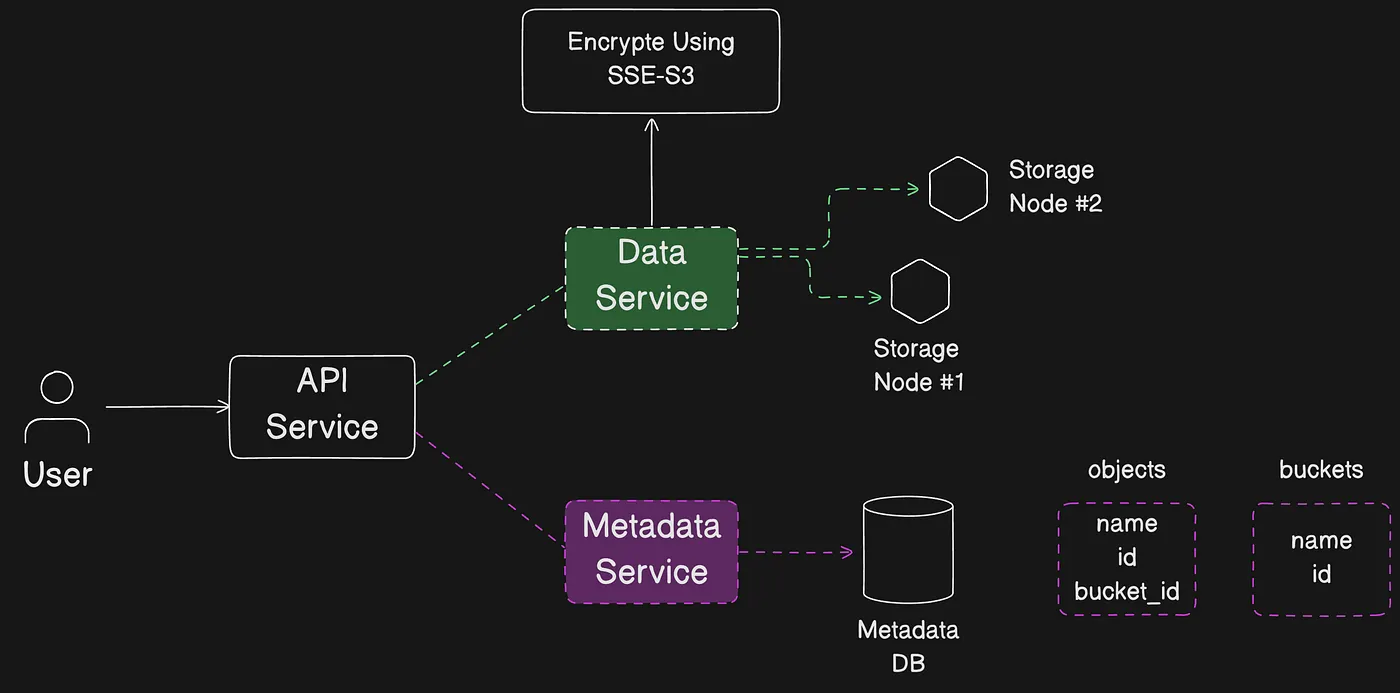 Luồng upload object lên S3 kèm mã hóa SSE-S3 mặc định
Luồng upload object lên S3 kèm mã hóa SSE-S3 mặc định
Khi upload object, nếu bạn muốn sử dụng loại mã hóa mặc định khác, bạn cũng có thể chỉ định server-side encryption với AWS Key Management Service (AWS KMS) keys (SSE-KMS) trong S3 PUT request hoặc thiết lập cấu hình mã hóa mặc định trong bucket đích để sử dụng SSE-KMS mã hóa dữ liệu.
Ngăn chặn upload object trùng key name
Bạn có thể kiểm tra sự tồn tại của object trong bucket trước khi tạo nó bằng conditional write trên các thao tác upload. Điều này có thể ngăn việc ghi đè dữ liệu hiện có. Conditional write sẽ xác nhận không có object nào với cùng key name đã tồn tại trong bucket khi upload.
import { S3Client, PutObjectCommand } from "@aws-sdk/client-s3";
// Initialize the S3 client
const s3Client = new S3Client({ region: 'us-east-2' });
// Define your bucket, object key, and the content to upload
const bucketName = 'your-bucket-name';
const objectKey = 'your-object-key';
const fileContent = 'My Amazing File Content';
async function uploadFileIfNotExists() {
try {
const params = {
Bucket: bucketName,
Key: objectKey,
Body: fileContent,
// If-None-Match set to "*" prevents overwriting an existing object
IfNoneMatch: "*",
};
const command = new PutObjectCommand(params);
const data = await s3Client.send(command);
console.log('File successfully uploaded!');
} catch (error) {
if (error.name === 'PreconditionFailed') {
console.log('File already exists. Aborting upload to prevent overwrite.');
} else {
console.error('Error uploading file:', error);
}
}
}Upload object bằng multipart upload
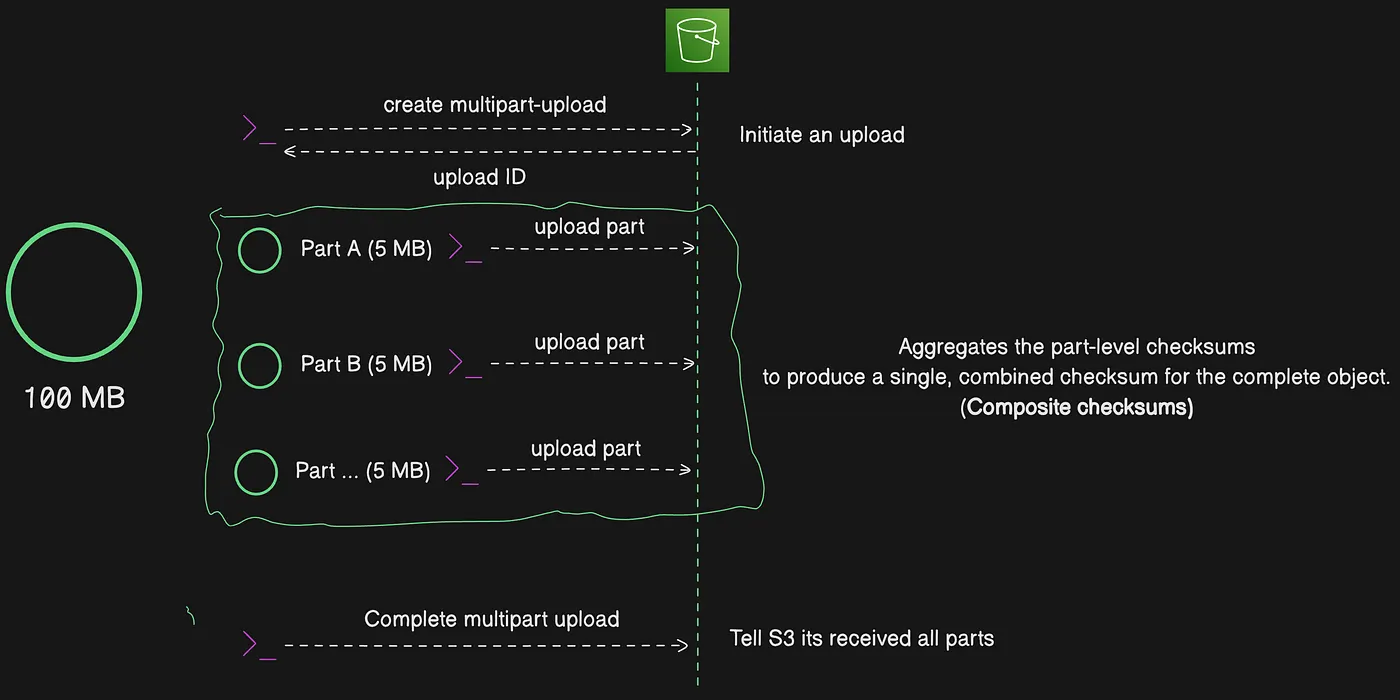
Multipart upload cho phép bạn upload một object duy nhất lên Amazon S3 dưới dạng một tập hợp các part (phần). Mỗi part là một phần liên tiếp của dữ liệu object. Bạn có thể upload các object part này một cách độc lập và theo bất kỳ thứ tự nào. Với mỗi lần upload, AWS client tự động tính toán checksum (giá trị kiểm tra tính toàn vẹn) của object và gửi kèm kích thước object như một phần của request. Nếu việc truyền bất kỳ part nào thất bại, bạn có thể truyền lại part đó mà không ảnh hưởng các part khác. Sau khi tất cả các part của object được upload, Amazon S3 sẽ ghép chúng lại để tạo thành object. Best practice là sử dụng multipart upload cho các object có kích thước từ 100 MB trở lên thay vì upload trong một thao tác đơn.
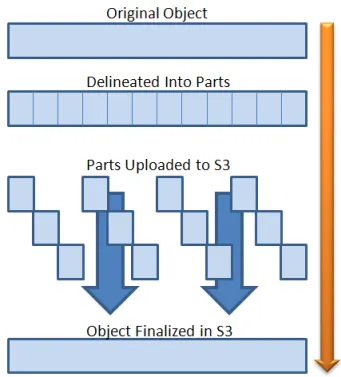 Object lớn được chia thành nhiều part để upload độc lập
Object lớn được chia thành nhiều part để upload độc lập
Sử dụng multipart upload mang lại các lợi thế sau:
- Improved throughput — Bạn có thể upload các part song song để cải thiện throughput (thông lượng).
- Quick recovery from any network issues — Kích thước part nhỏ hơn giúp giảm thiểu tác động của việc phải restart upload do lỗi mạng.
- Pause and resume object uploads — Bạn có thể upload object part theo thời gian. Sau khi khởi tạo multipart upload, không có thời hạn hết hạn; bạn phải hoàn tất hoặc dừng multipart upload một cách rõ ràng.
- Begin an upload before you know the final object size — Bạn có thể upload object ngay khi đang tạo nó.
Nên sử dụng multipart upload trong các tình huống sau:
- Nếu bạn upload object lớn qua mạng ổn định băng thông cao, hãy dùng multipart upload để tận dụng tối đa băng thông bằng cách upload các object part song song cho hiệu suất đa luồng (multi-threaded).
- Nếu bạn upload qua mạng không ổn định, hãy dùng multipart upload để tăng khả năng chịu lỗi mạng bằng cách tránh phải restart toàn bộ upload. Khi sử dụng multipart upload, bạn chỉ cần retry upload các part bị gián đoạn. Bạn không cần restart upload object từ đầu.
Quy trình multipart upload
Multipart upload là một quy trình ba bước: Bạn khởi tạo upload, upload các object part, và — sau khi đã upload tất cả các part — hoàn tất multipart upload. Khi nhận được yêu cầu hoàn tất multipart upload, Amazon S3 ghép object từ các part đã upload, và bạn có thể truy cập object giống như bất kỳ object nào khác trong bucket.
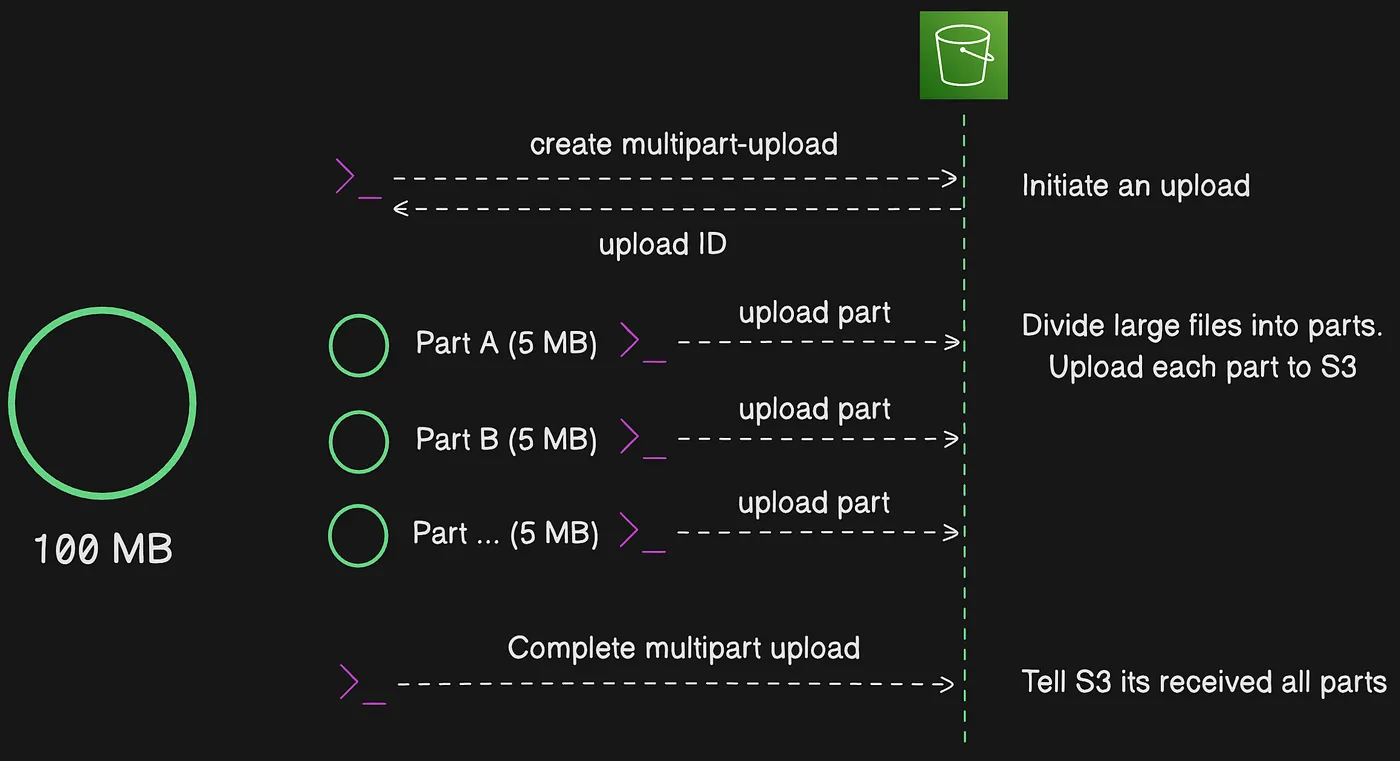 Quy trình ba bước của multipart upload qua một ví dụ cụ thể
Quy trình ba bước của multipart upload qua một ví dụ cụ thể
Bạn có thể liệt kê tất cả multipart upload đang thực hiện hoặc lấy danh sách các part đã upload cho một multipart upload cụ thể. Mỗi thao tác này được giải thích trong phần này.
Multipart upload initiation
Khi bạn gửi request để khởi tạo multipart upload, hãy đảm bảo chỉ định checksum type (loại checksum). Amazon S3 sau đó sẽ trả về phản hồi với upload ID, là định danh duy nhất cho multipart upload của bạn. Upload ID này được yêu cầu khi bạn upload part, liệt kê part, hoàn tất upload hoặc dừng upload.
Nếu bạn muốn cung cấp metadata mô tả object đang được upload, bạn phải cung cấp nó trong request khởi tạo multipart upload.
Parts upload
Khi upload một part, bạn phải chỉ định part number cùng với upload ID. Bạn có thể chọn bất kỳ part number nào từ 1 đến 10.000. Part number xác định duy nhất một part và vị trí của nó trong object đang upload. Part number bạn chọn không cần theo thứ tự liên tiếp (ví dụ, có thể là 1, 5 và 14). Lưu ý rằng nếu bạn upload part mới với cùng part number như part đã upload trước đó, part trước đó sẽ bị ghi đè.
Khi upload part, Amazon S3 trả về loại checksum algorithm cùng giá trị checksum cho mỗi part trong header của phản hồi. Với mỗi lần upload part, bạn phải ghi lại part number và giá trị ETag. Bạn phải đính kèm các giá trị này trong request hoàn tất multipart upload. Mỗi part sẽ có ETag riêng tại thời điểm upload. Tuy nhiên, sau khi multipart upload hoàn tất và tất cả part được hợp nhất, tất cả part thuộc về một ETag dưới dạng checksum của các checksum (checksum of checksums).
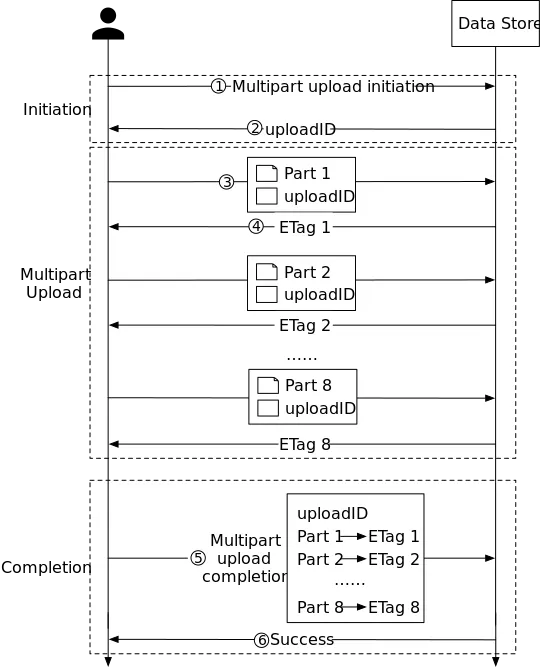 Mỗi part trả về ETag riêng, ghép lại thành checksum của các checksum
Mỗi part trả về ETag riêng, ghép lại thành checksum của các checksum
Multipart upload completion
Khi bạn hoàn tất multipart upload, Amazon S3 tạo object bằng cách ghép các part theo thứ tự tăng dần dựa trên part number. Nếu bất kỳ object metadata nào được cung cấp trong request khởi tạo multipart upload, Amazon S3 liên kết metadata đó với object. Sau request hoàn tất thành công, các part không còn tồn tại.
Request hoàn tất multipart upload của bạn phải bao gồm upload ID và danh sách part number cùng giá trị ETag tương ứng. Phản hồi của Amazon S3 bao gồm ETag xác định duy nhất dữ liệu object kết hợp. ETag này không nhất thiết là MD5 hash của dữ liệu object.
Khi bạn cung cấp full object checksum trong multipart upload, AWS SDK truyền checksum cho Amazon S3, và S3 xác nhận tính toàn vẹn object phía server, so sánh với giá trị nhận được. Sau đó, S3 lưu object nếu các giá trị khớp. Nếu hai giá trị không khớp, Amazon S3 từ chối request với lỗi BadDigest. Checksum của object cũng được lưu trong object metadata để bạn sau đó dùng xác nhận tính toàn vẹn dữ liệu.
Hủy multipart upload (Abort)
Sau khi khởi tạo multipart upload, bạn bắt đầu upload các part. Amazon S3 lưu trữ các part này và chỉ tạo object sau khi bạn upload tất cả part và gửi request hoàn tất multipart upload. Khi nhận request hoàn tất, Amazon S3 ghép các part và tạo object. Nếu bạn không gửi request hoàn tất thành công, S3 không ghép các part và không tạo object nào. Nếu bạn không muốn hoàn tất multipart upload sau khi đã upload part, bạn nên hủy (abort) multipart upload.
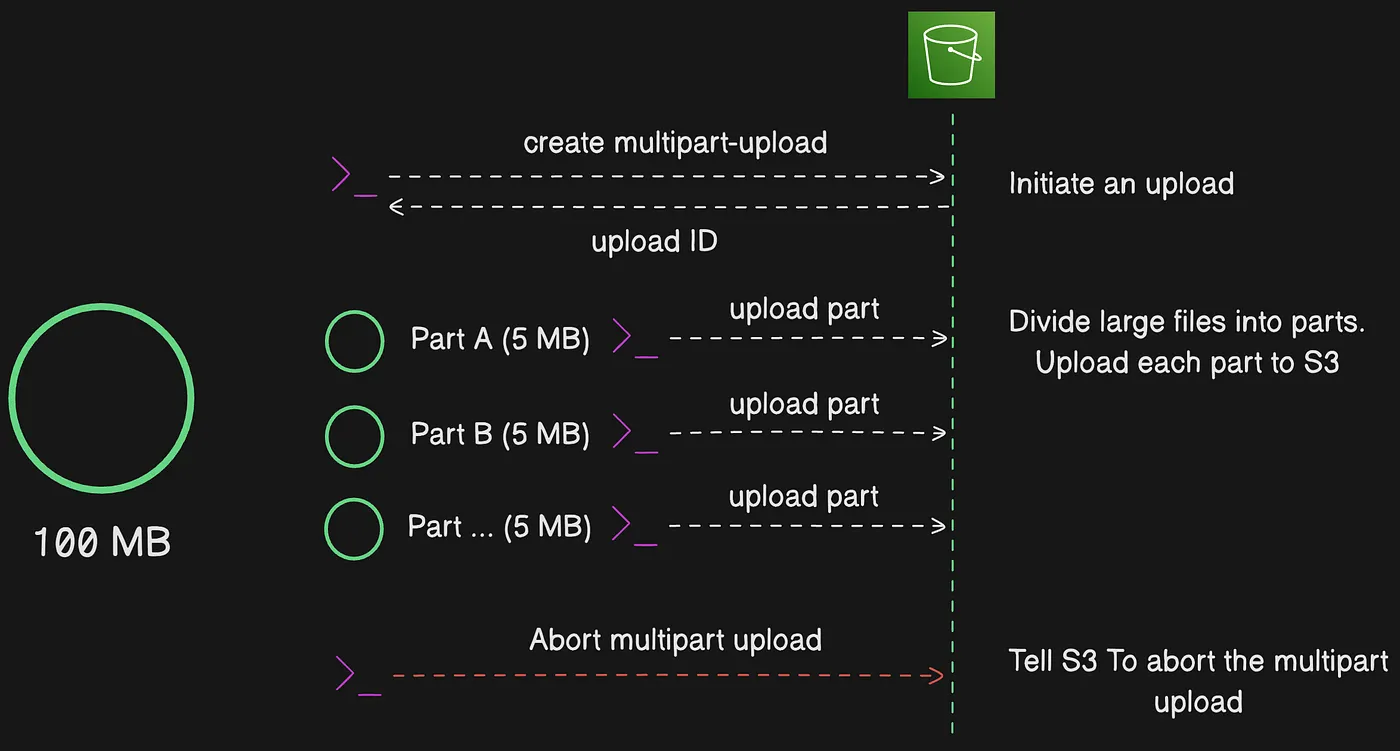 Hủy multipart upload để xóa các part đã upload dở
Hủy multipart upload để xóa các part đã upload dở
Bạn bị tính phí cho tất cả dung lượng lưu trữ liên quan đến các part đã upload. Nên luôn hoàn tất multipart upload hoặc dừng multipart upload để xóa các part đã upload.
Multipart upload đồng thời (Concurrent)
Trong môi trường phát triển phân tán, ứng dụng của bạn có thể khởi tạo nhiều bản cập nhật trên cùng object cùng lúc. Ứng dụng có thể khởi tạo nhiều multipart upload sử dụng cùng object key. Với mỗi upload, ứng dụng có thể upload part và gửi request hoàn tất upload cho Amazon S3 để tạo object. Khi bucket có bật S3 Versioning, việc hoàn tất multipart upload luôn tạo phiên bản mới. Khi bạn khởi tạo nhiều multipart upload sử dụng cùng object key trong bucket có bật versioning, phiên bản hiện tại của object được xác định bởi upload nào bắt đầu gần nhất (createdDate).
Ví dụ, bạn bắt đầu request CreateMultipartUpload cho một object lúc 10:00 AM. Sau đó, bạn gửi request CreateMultipartUpload thứ hai cho cùng object lúc 11:00 AM. Vì request thứ hai được gửi gần nhất, object được upload bởi request 11:00 AM sẽ trở thành phiên bản hiện tại, ngay cả khi upload đầu tiên hoàn tất sau upload thứ hai.
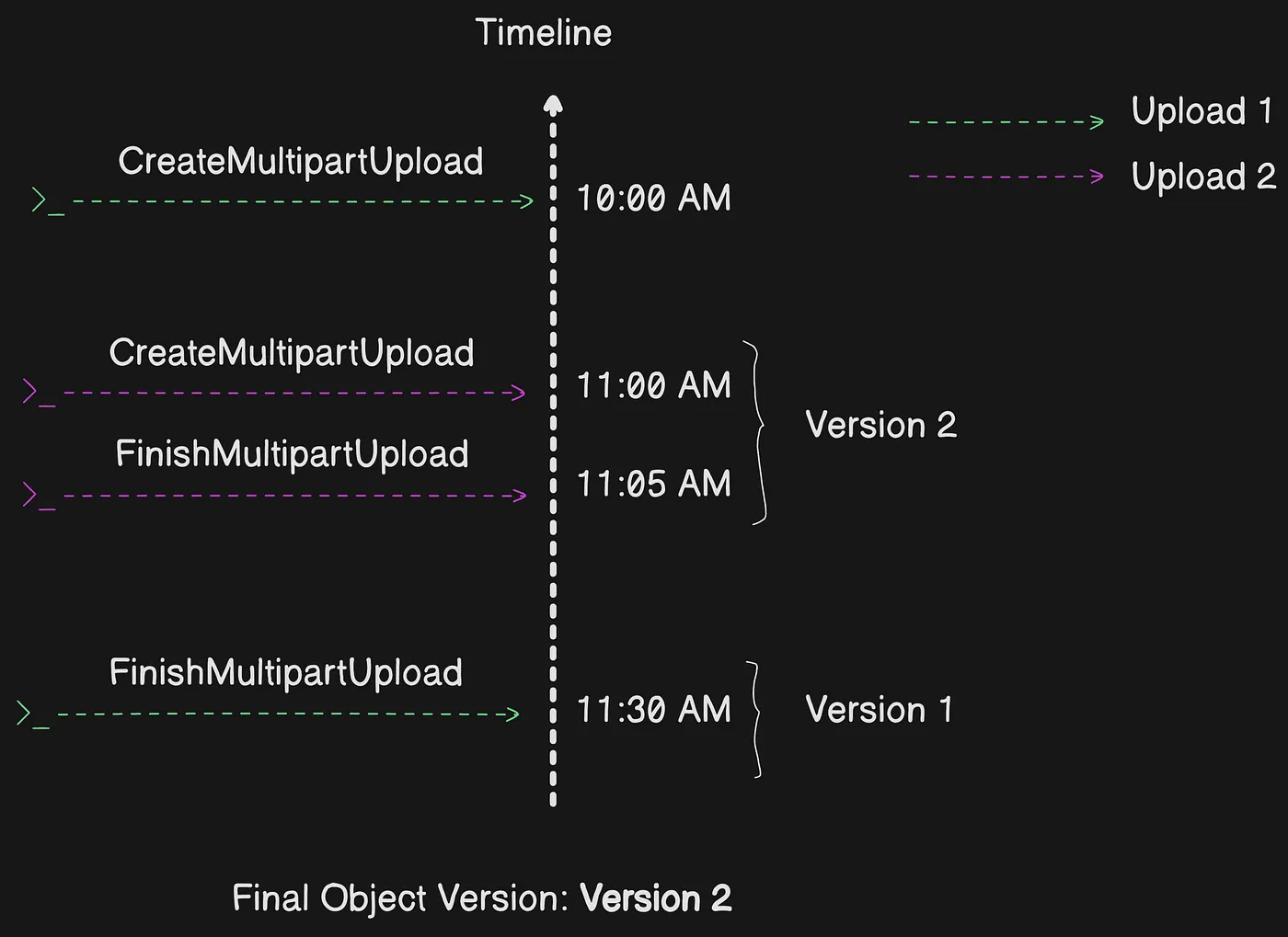 Hai multipart upload đồng thời, upload bắt đầu muộn hơn thành version hiện tại
Hai multipart upload đồng thời, upload bắt đầu muộn hơn thành version hiện tại
Đối với bucket không bật versioning, có thể bất kỳ request nào nhận được giữa thời điểm multipart upload được khởi tạo và khi nó hoàn tất, request khác có thể được ưu tiên.
Một ví dụ khác về khi multipart upload đồng thời có thể được ưu tiên là khi một thao tác khác xóa key sau khi bạn khởi tạo multipart upload với key đó. Trước khi bạn hoàn tất thao tác, phản hồi hoàn tất multipart upload có thể cho thấy tạo object thành công mà bạn không bao giờ thấy object đó.
Best practice là cấu hình lifecycle rule sử dụng action
AbortIncompleteMultipartUploadđể tối thiểu chi phí lưu trữ.
Thêm precondition vào các thao tác S3 với conditional requests
Bạn có thể sử dụng conditional requests để thêm precondition (điều kiện tiên quyết) vào các thao tác S3. Để sử dụng conditional requests, bạn thêm header bổ sung vào thao tác Amazon S3 API. Header này chỉ định điều kiện mà nếu không thỏa mãn, thao tác S3 sẽ thất bại.
Conditional reads được hỗ trợ cho các request GET, HEAD và COPY. Bạn có thể thêm precondition để trả về hoặc copy object dựa trên Entity tag (ETag) hoặc ngày sửa đổi cuối cùng (last modified date). Điều này có thể giới hạn thao tác S3 chỉ áp dụng cho object được cập nhật từ một ngày cụ thể. Bạn cũng có thể giới hạn thao tác S3 cho một ETag cụ thể, đảm bảo bạn chỉ trả về hoặc copy một phiên bản object cụ thể. (Xem tài liệu để biết danh sách đầy đủ API được hỗ trợ)
Conditional writes có thể đảm bảo không có object nào với cùng key name trong bucket khi thực hiện thao tác PUT. Điều này ngăn việc ghi đè object hiện có với key name trùng. Tương tự, bạn có thể sử dụng conditional write để kiểm tra ETag của object có thay đổi không trước khi cập nhật. Điều này ngăn việc ghi đè ngoài ý muốn lên object mà không biết trạng thái nội dung.
Các tình huống conditional write
Để hiểu conditional writes, hãy xem xét các tình huống sau khi hai client đang thực hiện thao tác trên cùng bucket.
Conditional writes trong multipart upload
Conditional writes không xem xét bất kỳ multipart upload request nào đang thực hiện vì chúng chưa phải là object hoàn chỉnh. Hãy xem ví dụ sau: Client 1 đang upload object bằng multipart upload. Trong quá trình multipart upload, Client 2 có thể ghi thành công cùng object đó với thao tác conditional write. Sau đó, khi Client 1 cố gắng hoàn tất multipart upload bằng conditional write, upload sẽ thất bại.
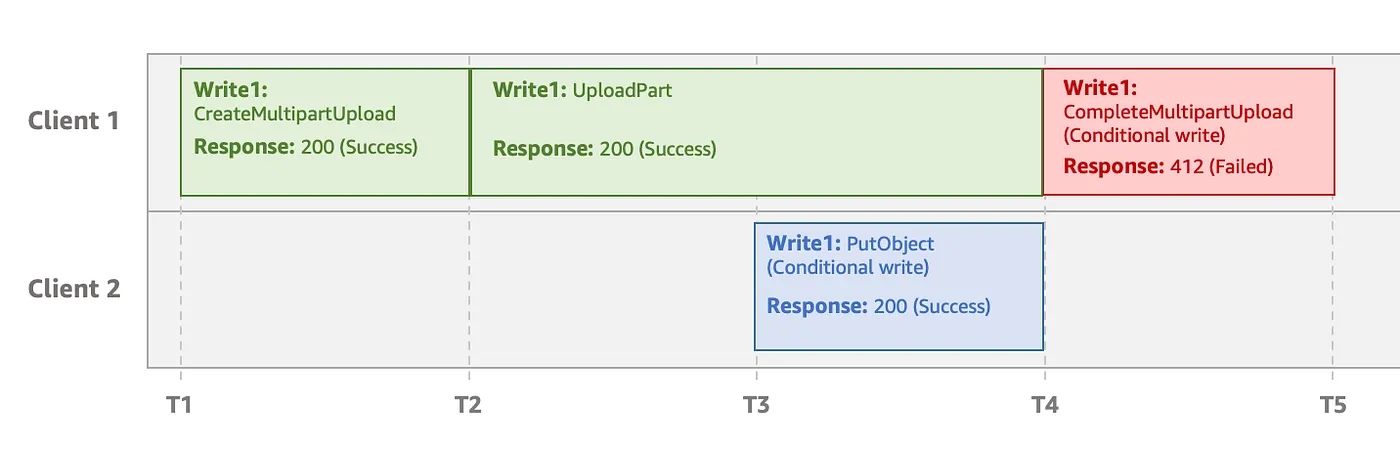 Conditional write bỏ qua multipart upload đang dở khiến Client 1 hoàn tất thất bại
Conditional write bỏ qua multipart upload đang dở khiến Client 1 hoàn tất thất bại
Xóa đồng thời trong multipart upload (Concurrent deletes)
Nếu request xóa thành công trước khi conditional write request hoàn tất, Amazon S3 trả về phản hồi 409 Conflict hoặc 404 Not Found cho thao tác ghi. Điều này là do request xóa được khởi tạo trước đó được ưu tiên hơn thao tác conditional write. Trong trường hợp này, bạn phải khởi tạo multipart upload mới.
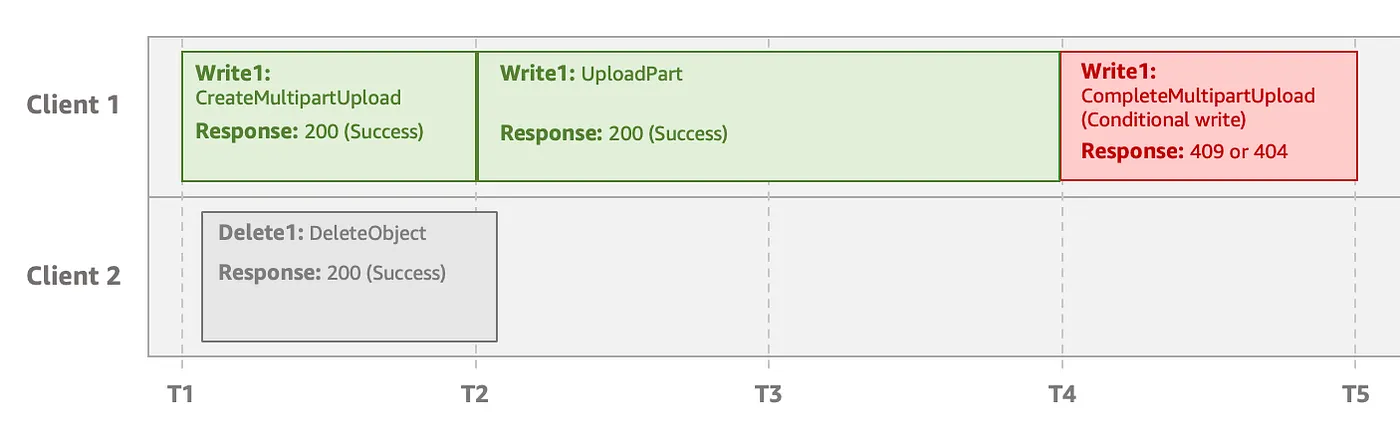 Xóa đồng thời được ưu tiên, conditional write nhận lỗi 409 hoặc 404
Xóa đồng thời được ưu tiên, conditional write nhận lỗi 409 hoặc 404
Kiểm tra tính toàn vẹn object trong Amazon S3
Amazon S3 sử dụng các giá trị checksum để xác nhận tính toàn vẹn của dữ liệu mà bạn upload hoặc download. Ngoài ra, bạn có thể yêu cầu tính toán giá trị checksum khác cho bất kỳ object nào bạn lưu trong Amazon S3. Bạn có thể chọn checksum algorithm khi upload, copy hoặc batch-copy dữ liệu.
Khi upload dữ liệu, Amazon S3 sử dụng algorithm mà bạn đã chọn để tính toán checksum phía server và xác nhận với giá trị được cung cấp trước khi lưu object và lưu checksum như một phần của object metadata. Quá trình xác nhận này hoạt động nhất quán trên các chế độ mã hóa, kích thước object và storage class cho cả single part và multipart upload. Tuy nhiên, khi copy hoặc batch copy dữ liệu, Amazon S3 tính checksum trên source object và di chuyển nó sang destination object.
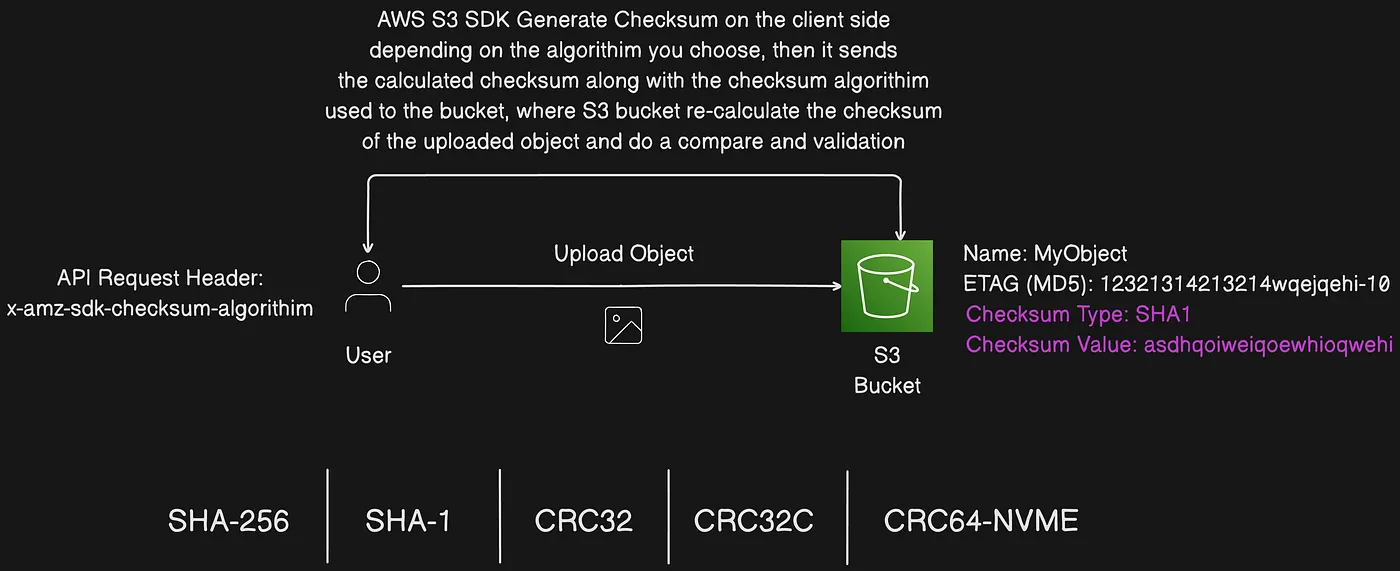 S3 tính checksum phía server và lưu cùng object metadata
S3 tính checksum phía server và lưu cùng object metadata
Với Amazon S3, bạn có thể chọn checksum algorithm để xác nhận dữ liệu khi upload. Checksum algorithm được chỉ định sau đó được lưu cùng object và có thể dùng để xác nhận tính toàn vẹn dữ liệu khi download.
Ngoài ra, bạn có thể cung cấp checksum với mỗi request sử dụng header Content-MD5.
Nếu source object không có checksum algorithm hoặc giá trị checksum được chỉ định, Amazon S3 sử dụng algorithm CRC64-NVME để tính giá trị checksum cho destination object.
Bây giờ chúng ta đã hiểu cách S3 checksum hoạt động, đã đến lúc xem xét một số cách và pattern có thể được sử dụng để xác nhận tính toàn vẹn object.
Full object và composite checksum types
Trong Amazon S3, có hai loại checksum được hỗ trợ:
- Full object checksums: Full object checksum được tính toán dựa trên toàn bộ nội dung của multipart upload, bao gồm tất cả dữ liệu từ byte đầu tiên của part đầu tiên đến byte cuối cùng của part cuối cùng.
 Full object checksum tính trên toàn bộ nội dung từ part đầu đến part cuối
Full object checksum tính trên toàn bộ nội dung từ part đầu đến part cuối
Điều này có nghĩa là bạn có thể cung cấp checksum algorithm cho API [MultipartUpload](https://docs.aws.amazon.com/AmazonS3/latest/API/API_MultipartUpload.html), đơn giản hóa công cụ xác nhận tính toàn vẹn vì bạn không còn cần theo dõi ranh giới các part cho object đã upload. Bạn có thể cung cấp checksum của toàn bộ object trong request [CompleteMultipartUpload](https://docs.aws.amazon.com/AmazonS3/latest/API/API_CompleteMultipartUpload.html), cùng với kích thước object.
- Composite checksums: Composite checksum được tính toán dựa trên các checksum riêng lẻ của từng part trong multipart upload. Thay vì tính checksum dựa trên toàn bộ nội dung dữ liệu, cách tiếp cận này tổng hợp các checksum cấp part (từ part đầu tiên đến part cuối cùng) để tạo ra một checksum kết hợp duy nhất cho object hoàn chỉnh.
 Composite checksum gộp các checksum cấp part thành một giá trị duy nhất
Composite checksum gộp các checksum cấp part thành một giá trị duy nhất
Đối với checksum cấp part trong multipart upload (hay composite checksum), Amazon S3 tính checksum cho từng part riêng lẻ bằng checksum algorithm đã chỉ định. Bạn có thể sử dụng [UploadPart](https://docs.aws.amazon.com/AmazonS3/latest/API/API_UploadPart.html) để cung cấp giá trị checksum cho mỗi part.
Khi checksum của mỗi part (cho toàn bộ object) được cung cấp, S3 sử dụng các giá trị checksum đã lưu của mỗi part để tính full object checksum nội bộ, so sánh với giá trị checksum được cung cấp. Điều này giúp giảm thiểu chi phí tính toán vì S3 có thể tính checksum của toàn bộ object bằng cách sử dụng checksum của các part.
Khi một object được upload dưới dạng multipart upload, entity tag (ETag) của object không phải là MD5 digest của toàn bộ object. Thay vào đó, Amazon S3 tính MD5 digest của từng part riêng lẻ khi upload. Các MD5 digest được dùng để xác định ETag cho object cuối cùng. Amazon S3 nối các byte của MD5 digest lại với nhau rồi tính MD5 digest của các giá trị đã nối. Trong bước tạo ETag cuối cùng, Amazon S3 thêm dấu gạch ngang cùng tổng số part vào cuối.
Sử dụng Content-MD5 khi upload object
Một cách khác để xác nhận tính toàn vẹn object sau khi upload là cung cấp MD5 digest của object khi upload. Nếu bạn tính MD5 digest cho object, bạn có thể cung cấp digest cùng lệnh PUT bằng header Content-MD5.
Sau khi upload object, Amazon S3 tính MD5 digest của object và so sánh với giá trị bạn cung cấp. Request chỉ thành công khi hai digest khớp nhau.
Cung cấp MD5 digest không bắt buộc, nhưng bạn có thể dùng nó để xác nhận tính toàn vẹn object như một phần của quá trình upload.
Tổ chức, liệt kê và làm việc với Objects
Trong Amazon S3, bạn có thể sử dụng prefix (tiền tố) để tổ chức lưu trữ. Prefix là một nhóm logic của các object trong bucket. Giá trị prefix tương tự như tên thư mục, cho phép bạn lưu trữ dữ liệu tương tự dưới cùng một thư mục trong bucket. Khi upload object theo chương trình, bạn có thể sử dụng prefix để tổ chức dữ liệu.
Trong Amazon S3 console, prefix được gọi là folder (thư mục). Bạn có thể xem tất cả object và folder trong S3 console bằng cách điều hướng đến bucket. Bạn cũng có thể xem thông tin về từng object, bao gồm các thuộc tính object.
Bạn có thể sử dụng prefix để tổ chức dữ liệu lưu trữ trong S3 bucket. Prefix là chuỗi ký tự ở đầu object key name. Prefix có thể có bất kỳ độ dài nào, tùy thuộc vào độ dài tối đa của object key name (1.024 bytes). Bạn có thể coi prefix như cách tổ chức dữ liệu tương tự thư mục. Tuy nhiên, prefix không phải là thư mục.
Tìm kiếm theo prefix giới hạn kết quả chỉ những key bắt đầu bằng prefix đã chỉ định. Delimiter khiến thao tác liệt kê gộp tất cả key có chung prefix thành một kết quả tóm tắt duy nhất.
Mục đích của tham số prefix và delimiter là giúp bạn tổ chức và duyệt các key theo cấu trúc phân cấp. Để làm điều này, trước tiên hãy chọn delimiter cho bucket, chẳng hạn như dấu gạch chéo (/), không xuất hiện trong bất kỳ key name nào bạn dự kiến. Bạn có thể sử dụng ký tự khác làm delimiter. Không có gì đặc biệt về ký tự gạch chéo (/), nhưng nó là prefix delimiter rất phổ biến. Tiếp theo, xây dựng key name bằng cách nối tất cả các cấp chứa của phân cấp, phân tách mỗi cấp bằng delimiter.
Ví dụ, nếu bạn lưu trữ thông tin về các thành phố, bạn có thể tự nhiên tổ chức theo châu lục, rồi theo quốc gia, rồi theo tỉnh hoặc bang. Vì các tên này thường không chứa dấu câu, bạn có thể dùng dấu gạch chéo (/) làm delimiter. Các ví dụ sau sử dụng delimiter gạch chéo (/):
- Europe/France/Nouvelle-Aquitaine/Bordeaux
- North America/Canada/Quebec/Montreal
- North America/USA/Washington/Bellevue
- North America/USA/Washington/Seattle
Nếu bạn lưu dữ liệu cho mọi thành phố trên thế giới theo cách này, việc quản lý namespace key phẳng sẽ trở nên cồng kềnh. Bằng cách sử dụng Prefix và Delimiter với thao tác liệt kê, bạn có thể dùng cấu trúc phân cấp đã tạo để liệt kê dữ liệu.
Liệt kê object sử dụng prefix và delimiter
Nếu bạn gửi request liệt kê với delimiter, bạn có thể duyệt cấu trúc phân cấp chỉ ở một cấp, bỏ qua và tóm tắt các key (có thể hàng triệu) lồng ở các cấp sâu hơn. Ví dụ, giả sử bạn có bucket (_amzn-s3-demo-bucket_) với các key sau:
sample.jpg
photos/2006/January/sample.jpg
photos/2006/February/sample2.jpg
photos/2006/February/sample3.jpg
photos/2006/February/sample4.jpg
Bucket mẫu chỉ có object sample.jpg ở cấp root. Để liệt kê chỉ các object cấp root trong bucket, bạn gửi GET request trên bucket với ký tự delimiter gạch chéo (/). Trong phản hồi, Amazon S3 trả về object key sample.jpg vì nó không chứa ký tự delimiter /. Tất cả các key khác chứa ký tự delimiter. Amazon S3 nhóm các key này và trả về một phần tử CommonPrefixes duy nhất với giá trị prefix photos/, là chuỗi con từ đầu các key này đến lần xuất hiện đầu tiên của delimiter đã chỉ định.
Download và Upload object với pre-signed URLs
Bạn có thể sử dụng presigned URLs để cấp quyền truy cập có giới hạn thời gian vào các object trong Amazon S3 mà không cần cập nhật bucket policy. Presigned URL có thể được nhập vào trình duyệt hoặc được chương trình sử dụng để tải xuống object. Credentials được sử dụng bởi presigned URL là của AWS user đã tạo URL.
Bạn cũng có thể sử dụng presigned URLs để cho phép ai đó upload một object cụ thể vào Amazon S3 bucket của bạn. Điều này cho phép upload mà không yêu cầu bên thứ ba có AWS security credentials hoặc permissions. Nếu object có cùng key đã tồn tại trong bucket như được chỉ định trong presigned URL, Amazon S3 sẽ thay thế object hiện có bằng object được upload.
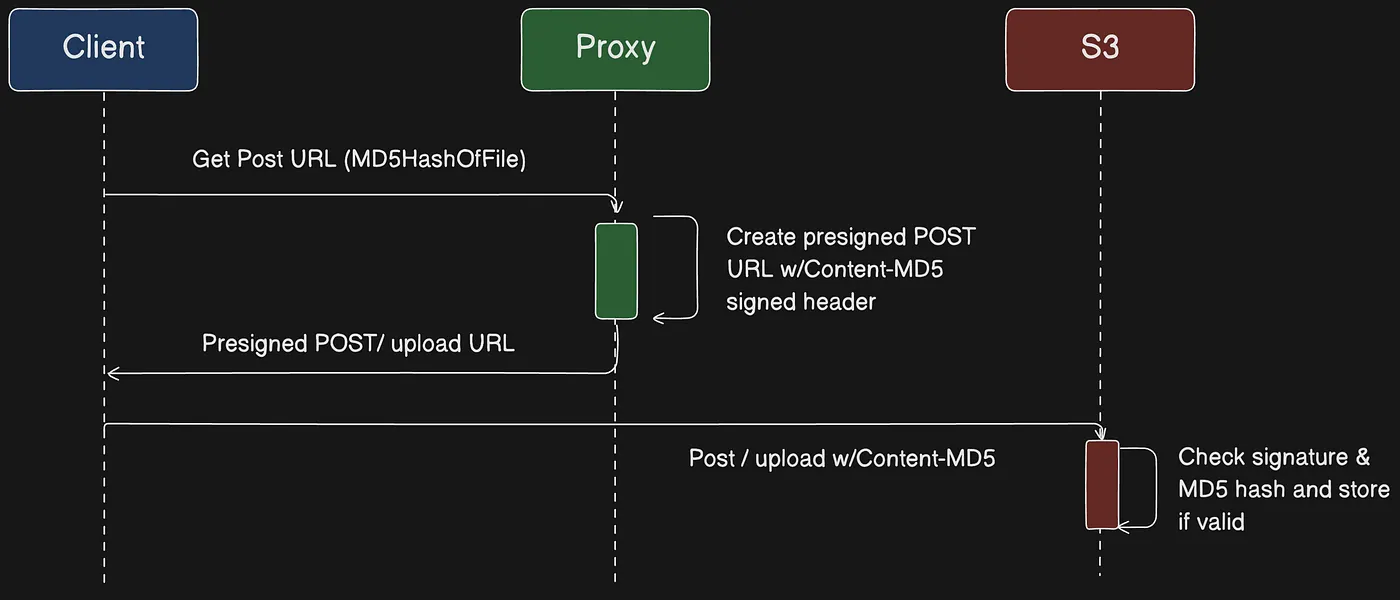 Luồng dùng presigned URL để cấp quyền truy cập object có giới hạn thời gian
Luồng dùng presigned URL để cấp quyền truy cập object có giới hạn thời gian
Bạn có thể sử dụng presigned URL nhiều lần, cho đến ngày và giờ hết hạn.
Khi tạo presigned URL, bạn phải cung cấp security credentials, sau đó chỉ định:
- Một Amazon S3 bucket
- Một object key (nếu download thì đây là object trong Amazon S3 bucket, nếu upload thì đây là tên file sẽ được upload)
- HTTP method (
GETđể download object hoặcPUTđể upload) - Khoảng thời gian hết hạn (expiration time interval)
Hiện tại, Amazon S3 presigned URLs không hỗ trợ sử dụng các checksum algorithm kiểm tra tính toàn vẹn dữ liệu (CRC32, CRC32C, SHA-1, SHA-256) khi upload object.
Để xác nhận tính toàn vẹn object sau khi upload, bạn có thể cung cấp MD5 digest của object khi upload bằng presigned URL.
Thời gian hết hạn cho presigned URLs
Nếu bạn tạo presigned URL bằng temporary token (token tạm thời), URL sẽ hết hạn khi token hết hạn. Nói chung, presigned URL hết hạn khi credential bạn dùng để tạo nó bị thu hồi, xóa hoặc vô hiệu hóa. Điều này đúng ngay cả khi URL được tạo với thời gian hết hạn muộn hơn.
S3 Access Points
Amazon S3 Access Points là tính năng của Amazon Simple Storage Service (S3) cho phép bạn tạo các cấu hình truy cập tùy chỉnh cho S3 bucket. Chúng đơn giản hóa việc quản lý và kiểm soát truy cập vào dữ liệu chia sẻ bằng cách cung cấp các endpoint duy nhất, mỗi endpoint có permissions và policies riêng. Đây là giải thích chi tiết:
Tại sao sử dụng S3 Access Points?
- Đơn giản hóa quản lý Permissions: Thay vì quản lý policy toàn bucket, bạn có thể tạo nhiều access point cho các user hoặc ứng dụng khác nhau, mỗi access point có policy cụ thể phù hợp với nhu cầu.
- Cải thiện bảo mật: Bằng cách cô lập access permissions qua các access point riêng lẻ, bạn giảm thiểu rủi ro truy cập do nhầm lẫn hoặc không được phép vào các phần khác của bucket.
- Mở rộng với Data Lakes: Cho các data lake quy mô lớn hoặc môi trường có nhiều team truy cập dữ liệu chia sẻ, access point giúp tinh gọn kiểm soát truy cập mà không làm phức tạp quản lý bucket policy.
Hãy lấy một ví dụ để hiểu sâu hơn về S3 Access Points. Bạn có Amazon S3 bucket tên data-lake-bucket lưu trữ các loại dữ liệu khác nhau:
sales-data/marketing-data/engineering-data/
Bạn muốn:
- Cung cấp cho Sales Team quyền truy cập chỉ vào
sales-data/. - Cho phép Marketing Team truy cập
marketing-data/và cho phép upload file chiến dịch. - Cho phép Engineering Team truy cập
engineering-data/nhưng giới hạn sử dụng nội bộ trong private VPC.
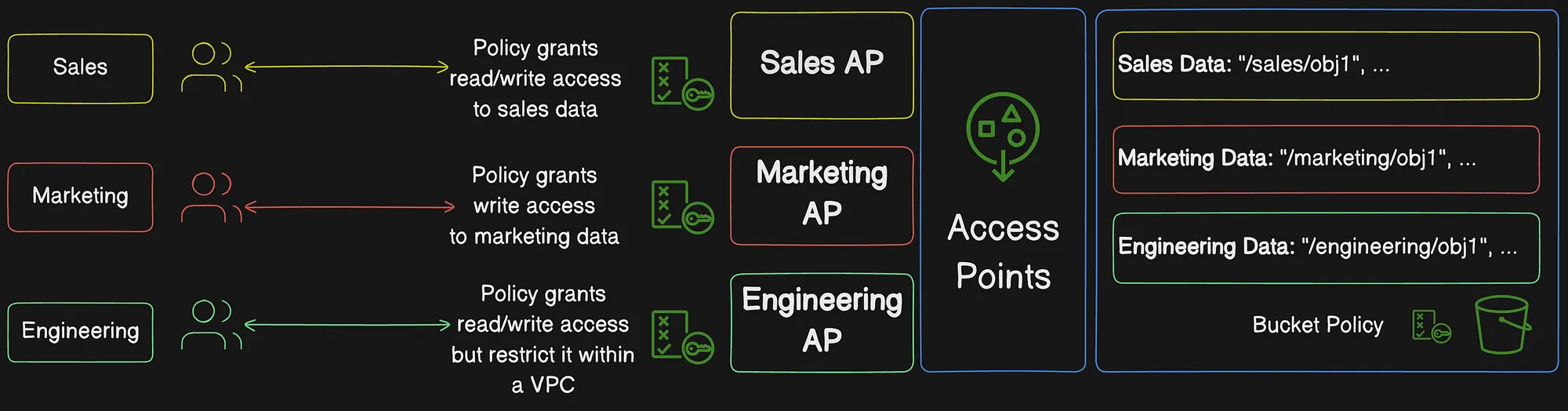 Mỗi team dùng một access point riêng với policy giới hạn theo prefix
Mỗi team dùng một access point riêng với policy giới hạn theo prefix
Biến đổi object với S3 Object Lambda
Với Amazon S3 Object Lambda, bạn có thể thêm code riêng vào các request Amazon S3 GET, LIST và HEAD để chỉnh sửa và xử lý dữ liệu khi nó được trả về cho ứng dụng. Bạn có thể sử dụng custom code để chỉnh sửa dữ liệu trả về từ S3 GET request nhằm lọc hàng, thay đổi kích thước và đóng watermark ảnh động, che dấu dữ liệu nhạy cảm (redact), và nhiều hơn nữa.
Bạn cũng có thể sử dụng S3 Object Lambda để chỉnh sửa output của S3 LIST request nhằm tạo view tùy chỉnh cho tất cả object trong bucket, và S3 HEAD request để chỉnh sửa object metadata như tên và kích thước object. Bạn có thể dùng S3 Object Lambda làm origin cho Amazon CloudFront distribution để tùy chỉnh dữ liệu cho end user, chẳng hạn như tự động thay đổi kích thước ảnh, chuyển đổi định dạng cũ (như từ JPEG sang WebP), hoặc loại bỏ metadata.
Cách S3 Object Lambda hoạt động
S3 Object Lambda sử dụng AWS Lambda function để tự động xử lý output của các S3 GET, LIST hoặc HEAD request tiêu chuẩn. AWS Lambda là dịch vụ compute serverless chạy code do khách hàng định nghĩa mà không cần quản lý tài nguyên compute bên dưới. Bạn có thể viết và chạy Lambda function tùy chỉnh, điều chỉnh data transformation cho use case cụ thể.
Sau khi cấu hình Lambda function, bạn gắn nó vào S3 Object Lambda service endpoint, được gọi là Object Lambda Access Point. Object Lambda Access Point sử dụng S3 access point tiêu chuẩn, được gọi là supporting access point, để truy cập Amazon S3.
Khi bạn gửi request đến Object Lambda Access Point, Amazon S3 tự động gọi Lambda function. Bất kỳ dữ liệu nào được truy xuất qua S3 GET, LIST hoặc HEAD request thông qua Object Lambda Access Point đều trả về kết quả đã biến đổi cho ứng dụng. Tất cả request khác được xử lý bình thường, như minh họa trong sơ đồ sau.
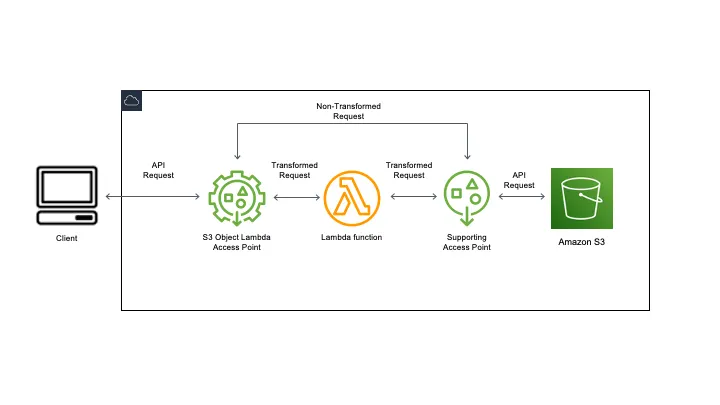 S3 Object Lambda gọi Lambda function để biến đổi dữ liệu khi trả về
S3 Object Lambda gọi Lambda function để biến đổi dữ liệu khi trả về
S3 Batch Operations
Bạn có thể sử dụng S3 Batch Operations để thực hiện các thao tác hàng loạt quy mô lớn trên Amazon S3 object. S3 Batch Operations có thể thực hiện một thao tác duy nhất trên danh sách Amazon S3 object mà bạn chỉ định. Một job duy nhất có thể thực hiện thao tác đã chỉ định trên hàng tỷ object chứa exabyte dữ liệu. Amazon S3 theo dõi tiến trình, gửi thông báo và lưu trữ báo cáo hoàn thành chi tiết của tất cả hành động, cung cấp trải nghiệm fully managed, có thể kiểm toán (auditable) và serverless. Bạn có thể sử dụng S3 Batch Operations qua Amazon S3 console, AWS CLI, AWS SDK hoặc Amazon S3 REST API.
Sử dụng S3 Batch Operations để copy object và thiết lập object tag hoặc access control list (ACL). Bạn cũng có thể khởi tạo khôi phục object từ S3 Glacier Flexible Retrieval hoặc gọi AWS Lambda function để thực hiện các hành động tùy chỉnh trên object. Bạn có thể thực hiện các thao tác này trên danh sách object tùy chỉnh, hoặc sử dụng Amazon S3 Inventory report để dễ dàng tạo danh sách object. Amazon S3 Batch Operations sử dụng cùng Amazon S3 API operation mà bạn đã sử dụng với Amazon S3.
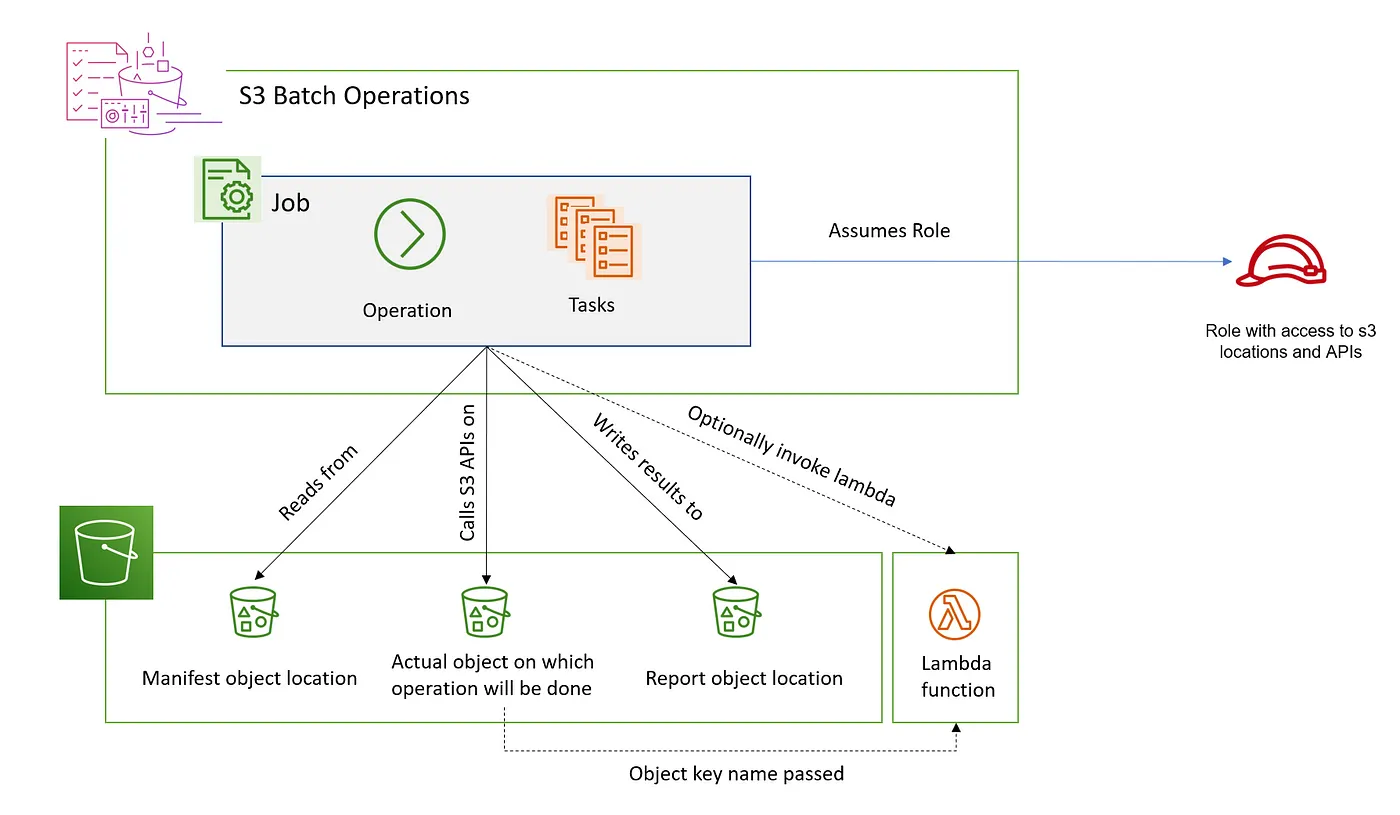 S3 Batch Operations chạy một thao tác trên hàng loạt object theo manifest
S3 Batch Operations chạy một thao tác trên hàng loạt object theo manifest
Thuật ngữ
Phần này sử dụng các thuật ngữ manifest, job, operation và task, được định nghĩa như sau:
Manifest
Manifest là một Amazon S3 object chứa các object key mà bạn muốn Amazon S3 thao tác. Nếu muốn tạo Batch Operations job, bạn phải cung cấp manifest. Manifest do người dùng tạo phải chứa tên bucket, object key, và tùy chọn, object version cho mỗi object. Nếu bạn cung cấp manifest do người dùng tạo, nó phải ở dạng Amazon S3 Inventory report hoặc file CSV.
Bạn cũng có thể để Amazon S3 tự động tạo manifest dựa trên tiêu chí lọc object mà bạn chỉ định khi tạo job. Tùy chọn này có sẵn cho S3 Batch Replication job mà bạn tạo trong Amazon S3 console, hoặc cho bất kỳ loại job nào mà bạn tạo bằng AWS Command Line Interface (AWS CLI), AWS SDK hoặc Amazon S3 REST API.
Job
Job là đơn vị công việc cơ bản cho S3 Batch Operations. Job chứa tất cả thông tin cần thiết để chạy thao tác đã chỉ định trên các object được liệt kê trong manifest. Sau khi bạn cung cấp thông tin và yêu cầu job bắt đầu, job thực hiện thao tác cho mỗi object trong manifest.
Operation
Operation là loại API action, chẳng hạn như copy object, mà bạn muốn Batch Operations job chạy. Mỗi job thực hiện một loại operation duy nhất trên tất cả object được chỉ định trong manifest.
Task
Task là đơn vị thực thi cho job. Task đại diện cho một lần gọi duy nhất đến Amazon S3 hoặc AWS Lambda API operation để thực hiện operation của job trên một object. Trong suốt vòng đời của job, S3 Batch Operations tạo một task cho mỗi object được chỉ định trong manifest.
S3 Inventory
Bạn có thể sử dụng Amazon S3 Inventory để quản lý lưu trữ. Ví dụ, bạn có thể dùng nó để kiểm toán và báo cáo về trạng thái replication và encryption của object cho các nhu cầu kinh doanh, tuân thủ và pháp lý. Bạn cũng có thể đơn giản hóa và tăng tốc workflow kinh doanh và big data job bằng Amazon S3 Inventory, cung cấp giải pháp thay thế theo lịch cho các S3 synchronous List API operation.
Amazon S3 Inventory không sử dụng
ListAPI operation để kiểm toán object và không ảnh hưởng đến request rate của bucket.
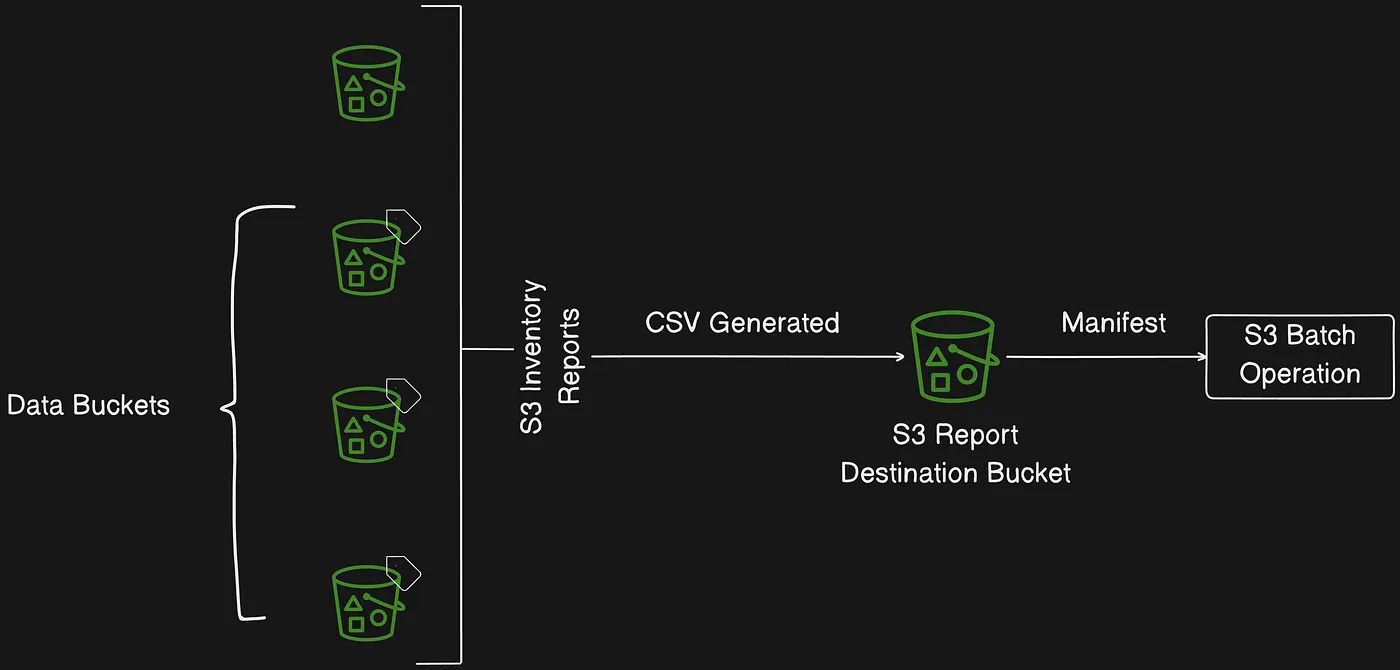 S3 Inventory xuất file CSV làm manifest đầu vào cho S3 Batch Operations
S3 Inventory xuất file CSV làm manifest đầu vào cho S3 Batch Operations
S3 Inventory và S3 Batch Operations đóng vai trò bổ sung cho nhau: S3 Inventory tạo file CSV dựa trên các object trong bucket, còn S3 Batch Operations có thể sử dụng các file CSV đó để chạy các job cụ thể.
Cách S3 Batch Operations job hoạt động
Job là đơn vị công việc cơ bản cho S3 Batch Operations. Job chứa tất cả thông tin cần thiết để chạy thao tác đã chỉ định trên danh sách object. Để tạo job, bạn cung cấp cho S3 Batch Operations danh sách object và chỉ định hành động cần thực hiện trên các object đó.
Batch job thực hiện thao tác đã chỉ định trên mọi object có trong manifest. Manifest liệt kê các object mà bạn muốn batch job xử lý và được lưu dưới dạng object trong bucket. Bạn có thể sử dụng báo cáo comma-separated values (CSV) làm manifest, giúp dễ dàng tạo danh sách lớn các object nằm trong bucket. Bạn cũng có thể chỉ định manifest ở định dạng CSV đơn giản cho phép thực hiện batch operation trên danh sách tùy chỉnh các object trong một bucket.
Sau khi tạo job, Amazon S3 xử lý danh sách object trong manifest và chạy thao tác đã chỉ định trên mỗi object. Khi job đang chạy, bạn có thể giám sát tiến trình theo chương trình hoặc qua Amazon S3 console. Bạn cũng có thể cấu hình job để tạo báo cáo hoàn thành khi kết thúc.
Data Encryption
Bảo vệ dữ liệu (data protection) đề cập đến việc bảo vệ dữ liệu khi đang truyền (in transit — khi di chuyển đến và từ Amazon S3) và khi lưu trữ (at rest — khi được lưu trên ổ đĩa trong data center Amazon S3). Bạn có thể bảo vệ dữ liệu đang truyền bằng Secure Socket Layer/Transport Layer Security (SSL/TLS) hoặc client-side encryption. Để bảo vệ dữ liệu lưu trữ trong Amazon S3, bạn có các tùy chọn sau:
- Server-side encryption — Amazon S3 mã hóa object trước khi lưu trên ổ đĩa trong data center AWS rồi giải mã object khi bạn tải xuống. Tất cả Amazon S3 bucket đều được cấu hình mã hóa mặc định, và tất cả object mới được upload lên S3 bucket đều tự động được mã hóa khi lưu trữ.
- Client-side encryption — Bạn mã hóa dữ liệu phía client và upload dữ liệu đã mã hóa lên Amazon S3. Trong trường hợp này, bạn quản lý quy trình mã hóa, encryption key và các công cụ liên quan.
Server-side encryption
Server-side encryption là mã hóa dữ liệu tại đích bởi ứng dụng hoặc dịch vụ nhận nó. Amazon S3 mã hóa dữ liệu ở cấp object khi ghi vào ổ đĩa trong data center AWS và giải mã cho bạn khi truy cập. Miễn là bạn xác thực request và có access permission, không có sự khác biệt trong cách bạn truy cập object đã mã hóa hoặc chưa mã hóa. Ví dụ, nếu bạn chia sẻ object bằng presigned URL, URL đó hoạt động giống nhau cho cả object đã mã hóa và chưa mã hóa. Ngoài ra, khi liệt kê object trong bucket, list API operation trả về danh sách tất cả object, bất kể chúng có được mã hóa hay không.
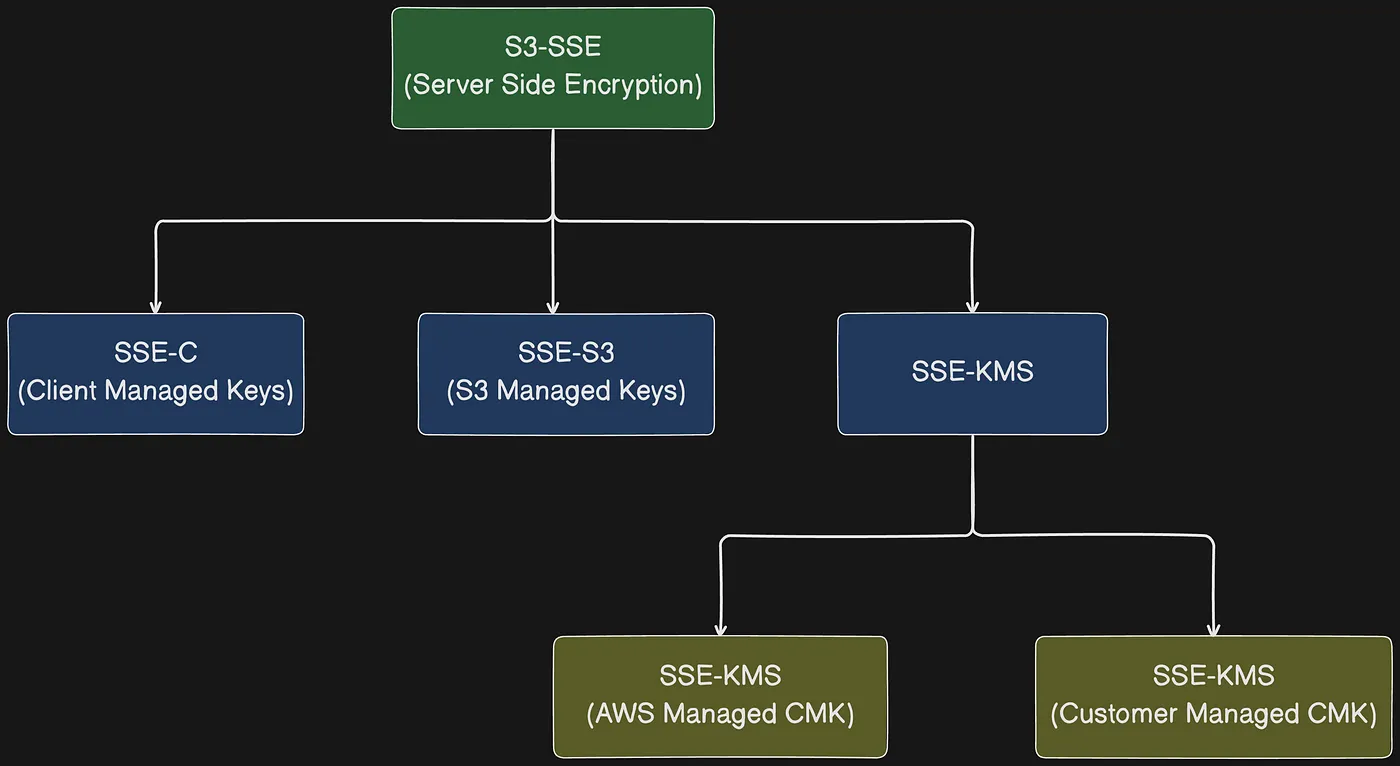 Các tùy chọn mã hóa server-side và client-side trong S3
Các tùy chọn mã hóa server-side và client-side trong S3
Tất cả Amazon S3 bucket đều được cấu hình mã hóa mặc định, và tất cả object mới upload lên S3 bucket đều tự động được mã hóa khi lưu trữ. Server-side encryption với Amazon S3 managed keys (SSE-S3) là cấu hình mã hóa mặc định cho mọi bucket trong Amazon S3. Để sử dụng loại mã hóa khác, bạn có thể chỉ định loại server-side encryption trong S3 PUT request, hoặc thiết lập cấu hình mã hóa mặc định trong bucket đích.
Nếu muốn chỉ định loại mã hóa khác trong PUT request, bạn có thể sử dụng server-side encryption với AWS Key Management Service (AWS KMS) keys (SSE-KMS), dual-layer server-side encryption với AWS KMS keys (DSSE-KMS), hoặc server-side encryption với customer-provided keys (SSE-C). Nếu muốn thiết lập cấu hình mã hóa mặc định khác trong bucket đích, bạn có thể sử dụng SSE-KMS hoặc DSSE-KMS.
Server-side encryption với Amazon S3 managed keys (SSE-S3)
Tất cả object upload mới lên Amazon S3 bucket đều được mã hóa mặc định bằng server-side encryption với Amazon S3 managed keys (SSE-S3).
Server-side encryption bảo vệ dữ liệu khi lưu trữ. Amazon S3 mã hóa mỗi object bằng một key duy nhất. Như biện pháp bảo vệ bổ sung, nó mã hóa chính key đó bằng một key được xoay vòng (rotate) định kỳ. Amazon S3 server-side encryption sử dụng 256-bit Advanced Encryption Standard Galois/Counter Mode (AES-GCM) để mã hóa tất cả object được upload.
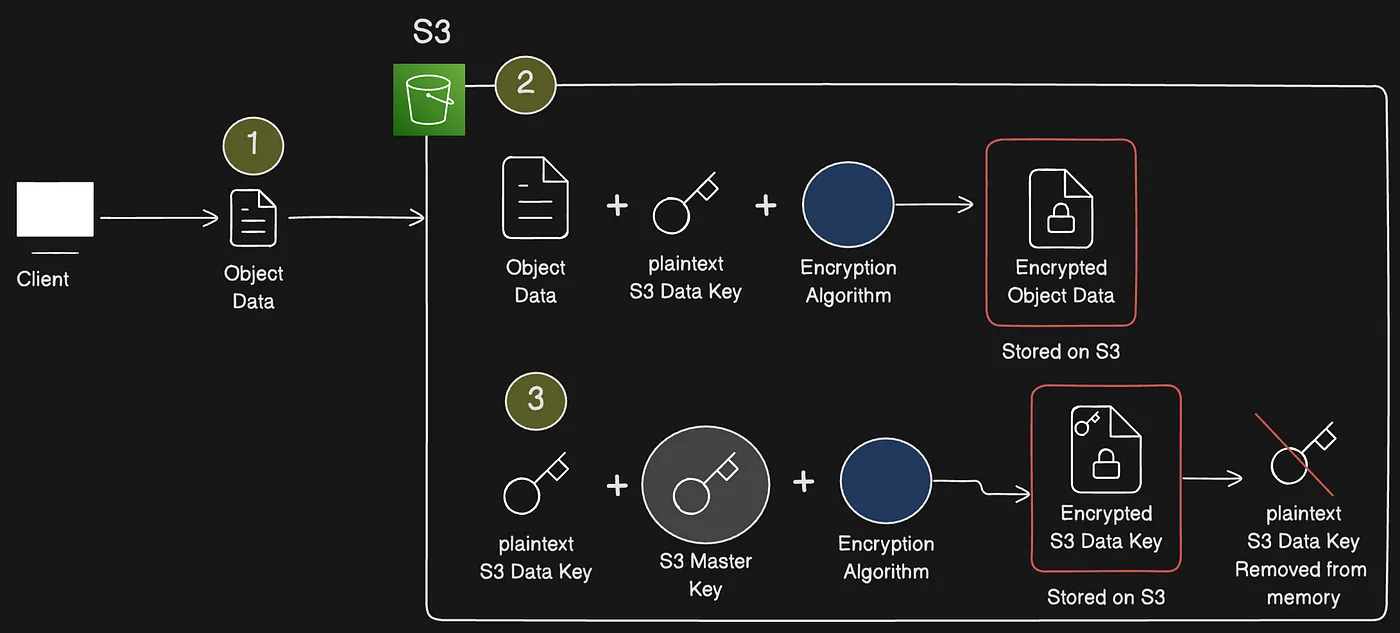 Luồng SSE-S3 dùng root key mã hóa data key cho từng object
Luồng SSE-S3 dùng root key mã hóa data key cho từng object
Quá trình mã hóa diễn ra với sự hỗ trợ của “root/master key” do AWS S3 tạo, được AWS S3 quản lý hoàn toàn.
- “root/master key” của AWS S3 tạo một “Data Key” riêng biệt cho mỗi object được upload lên S3.
- “Data Key” được dùng để mã hóa object.
- “root/master key” của AWS S3 được dùng để mã hóa “Data Key”.
- Sau đó cả “encrypted object” và “encrypted Data Key” được lưu trữ cạnh nhau trong S3 storage.
- “Data Key” đã tạo sau đó bị loại bỏ ngay sau quá trình mã hóa.
- Vì đây là mã hóa đối xứng (symmetric encryption), việc giải mã object có thể thực hiện bằng “root/master key” của AWS S3. “root/master key” được dùng để giải mã “encrypted Data Key”, sau đó có thể dùng để giải mã object.
Không có phí bổ sung cho việc sử dụng server-side encryption với Amazon S3 managed keys (SSE-S3). Tuy nhiên, request để cấu hình tính năng mã hóa mặc định phát sinh phí Amazon S3 request tiêu chuẩn.
Server-side encryption với AWS KMS keys (SSE-KMS)
AWS KMS là dịch vụ kết hợp phần cứng và phần mềm an toàn, có tính sẵn sàng cao để cung cấp hệ thống quản lý key được mở rộng cho đám mây. Amazon S3 sử dụng server-side encryption với AWS KMS (SSE-KMS) để mã hóa S3 object data.
Ngoài ra, khi SSE-KMS được yêu cầu cho object, S3 checksum (như một phần của object metadata) được lưu ở dạng mã hóa.
Khi sử dụng server-side encryption với AWS KMS (SSE-KMS), bạn có thể dùng AWS managed key mặc định, hoặc chỉ định customer managed key mà bạn đã tạo. AWS KMS hỗ trợ envelope encryption (mã hóa phong bì). S3 sử dụng tính năng envelope encryption của AWS KMS để bảo vệ dữ liệu thêm. Envelope encryption là thực hành mã hóa plain text data bằng data key, sau đó mã hóa data key đó bằng KMS key.
Object được mã hóa bằng SSE-KMS với AWS managed keys không thể chia sẻ cross-account. Nếu cần chia sẻ dữ liệu SSE-KMS cross-account, bạn phải sử dụng customer managed key từ AWS KMS.
Nếu muốn sử dụng customer managed key cho SSE-KMS, hãy tạo symmetric encryption customer managed key trước khi cấu hình SSE-KMS. Sau đó, khi cấu hình SSE-KMS cho bucket, chỉ định customer managed key hiện có.
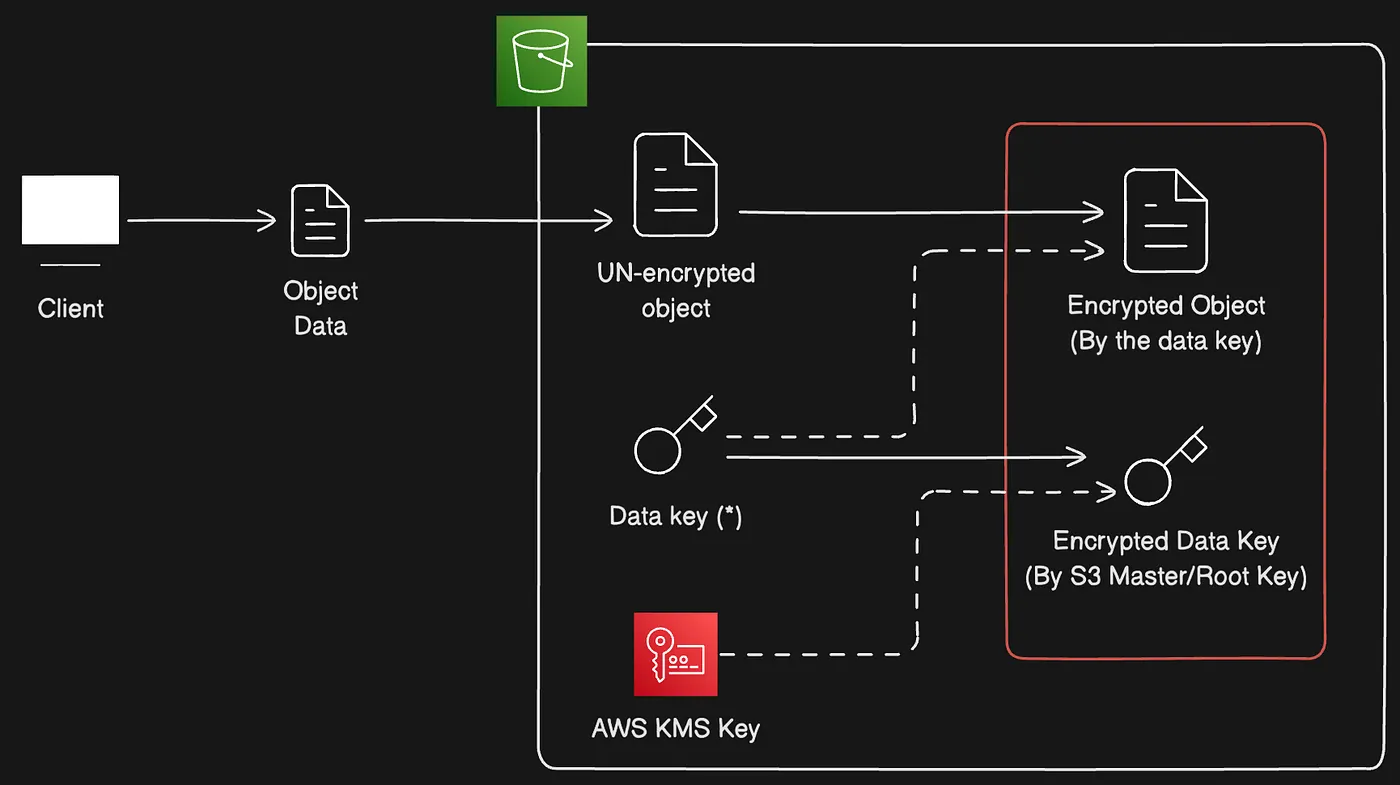 Luồng SSE-KMS dùng KMS key và envelope encryption thay cho root key
Luồng SSE-KMS dùng KMS key và envelope encryption thay cho root key
Trong phương pháp này, AWS ủy quyền “root/master key” cho AWS “KMS key”, cho phép có giải pháp linh hoạt hơn trong việc khắc phục một số hạn chế đã thảo luận trước đó.
- AWS “KMS key” có thể tạo “Data Key” duy nhất để mã hóa mỗi object upload lên S3. Điều này khá giống phương pháp SSE-S3 nhưng về cơ bản thay thế “root/master key” của SSE-S3 bằng AWS “KMS key”.
- Với cách tiếp cận AWS “KMS Key”, bạn có khả năng tạo “KMS Key” riêng, được gọi là “Customer Managed CMK”. Điều này cho phép bạn áp dụng permissions, xoay vòng key và có phân tách vai trò (role separation) mạnh mẽ.
- Phân tách vai trò cho AWS “KMS Key” có thể thực hiện bằng cách giới hạn vai trò AWS administrator cho “KMS Key” được chỉ định.
S3 Bucket Keys
Amazon S3 Bucket Keys giảm chi phí Amazon S3 server-side encryption với AWS Key Management Service (AWS KMS) keys (SSE-KMS). Sử dụng key cấp bucket cho SSE-KMS có thể giảm chi phí AWS KMS request lên đến 99% bằng cách giảm traffic request từ Amazon S3 đến AWS KMS. Chỉ với vài click trong AWS Management Console, và không cần thay đổi ứng dụng client, bạn có thể cấu hình bucket sử dụng S3 Bucket Key cho SSE-KMS encryption trên object mới.
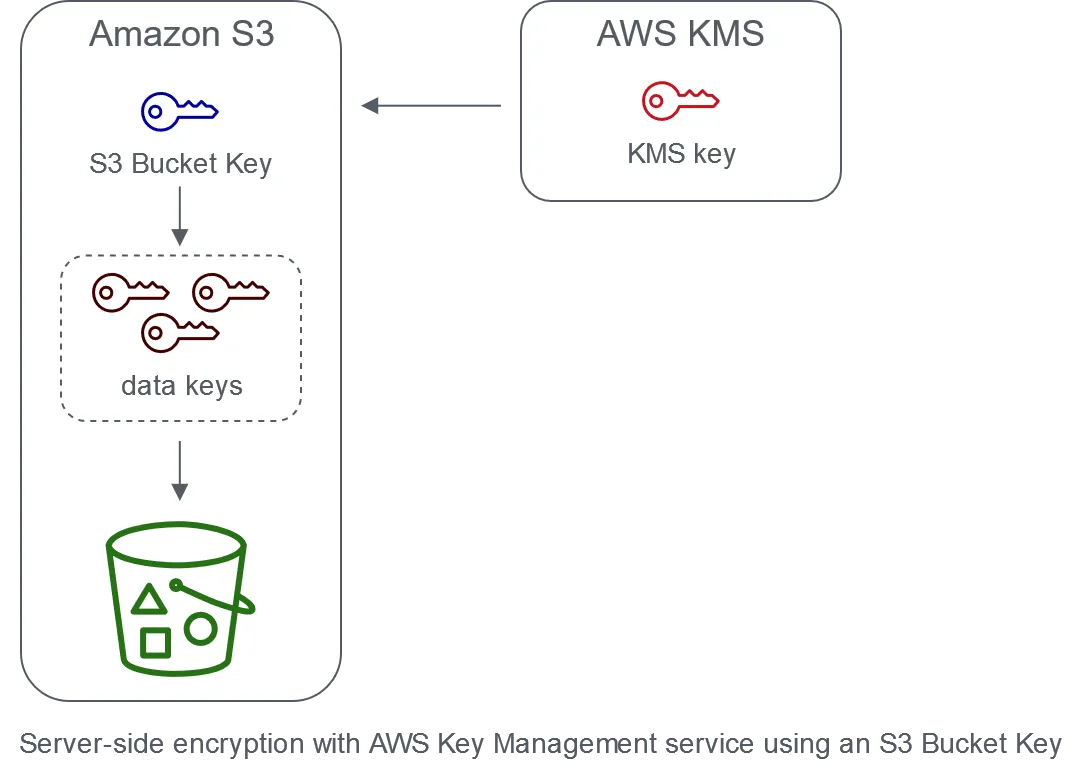 S3 Bucket Key giảm số lần gọi AWS KMS cho object dùng SSE-KMS
S3 Bucket Key giảm số lần gọi AWS KMS cho object dùng SSE-KMS
Các workload truy cập hàng triệu hoặc hàng tỷ object được mã hóa bằng SSE-KMS có thể tạo ra lượng lớn request đến AWS KMS. Khi sử dụng SSE-KMS bảo vệ dữ liệu mà không có S3 Bucket Key, Amazon S3 sử dụng AWS KMS data key riêng cho mỗi object. Trong trường hợp này, Amazon S3 gọi AWS KMS mỗi lần có request đến object đã mã hóa KMS.
Khi cấu hình bucket sử dụng S3 Bucket Key cho SSE-KMS, AWS tạo bucket-level key ngắn hạn từ AWS KMS, sau đó tạm giữ nó trong S3. Bucket-level key này sẽ tạo data key cho object mới trong vòng đời của nó. S3 Bucket Keys được sử dụng trong khoảng thời gian giới hạn trong Amazon S3, giảm nhu cầu S3 phải gửi request đến AWS KMS để hoàn tất thao tác mã hóa.
Dual-layer server-side encryption với AWS KMS keys (DSSE-KMS)
Sử dụng dual-layer server-side encryption với AWS Key Management Service (AWS KMS) keys (DSSE-KMS) áp dụng hai lớp mã hóa cho object khi upload lên Amazon S3. DSSE-KMS giúp bạn dễ dàng đáp ứng tiêu chuẩn tuân thủ yêu cầu áp dụng mã hóa nhiều lớp (multilayer encryption) cho dữ liệu và có toàn quyền kiểm soát encryption key.
Khi sử dụng DSSE-KMS với Amazon S3 bucket, AWS KMS keys phải ở cùng Region với bucket. Ngoài ra, khi DSSE-KMS được yêu cầu cho object, S3 checksum là một phần của object metadata được lưu ở dạng mã hóa.
Server-side encryption với customer-provided keys (SSE-C)
Server-side encryption là bảo vệ dữ liệu khi lưu trữ. Server-side encryption chỉ mã hóa dữ liệu object, không mã hóa object metadata. Bằng cách sử dụng server-side encryption với customer-provided keys (SSE-C), bạn có thể lưu trữ dữ liệu được mã hóa bằng encryption key của riêng mình. Với encryption key bạn cung cấp trong request, Amazon S3 quản lý mã hóa dữ liệu khi ghi vào ổ đĩa và giải mã khi truy cập object. Do đó, bạn không cần duy trì code để thực hiện mã hóa và giải mã. Điều duy nhất bạn cần làm là quản lý encryption key mà bạn cung cấp.
Khi upload object, Amazon S3 sử dụng encryption key bạn cung cấp để áp dụng AES-256 encryption cho dữ liệu. Amazon S3 sau đó xóa encryption key khỏi bộ nhớ. Khi truy xuất object, bạn phải cung cấp cùng encryption key trong request. Amazon S3 trước tiên xác nhận encryption key bạn cung cấp khớp, sau đó giải mã object trước khi trả về dữ liệu object.
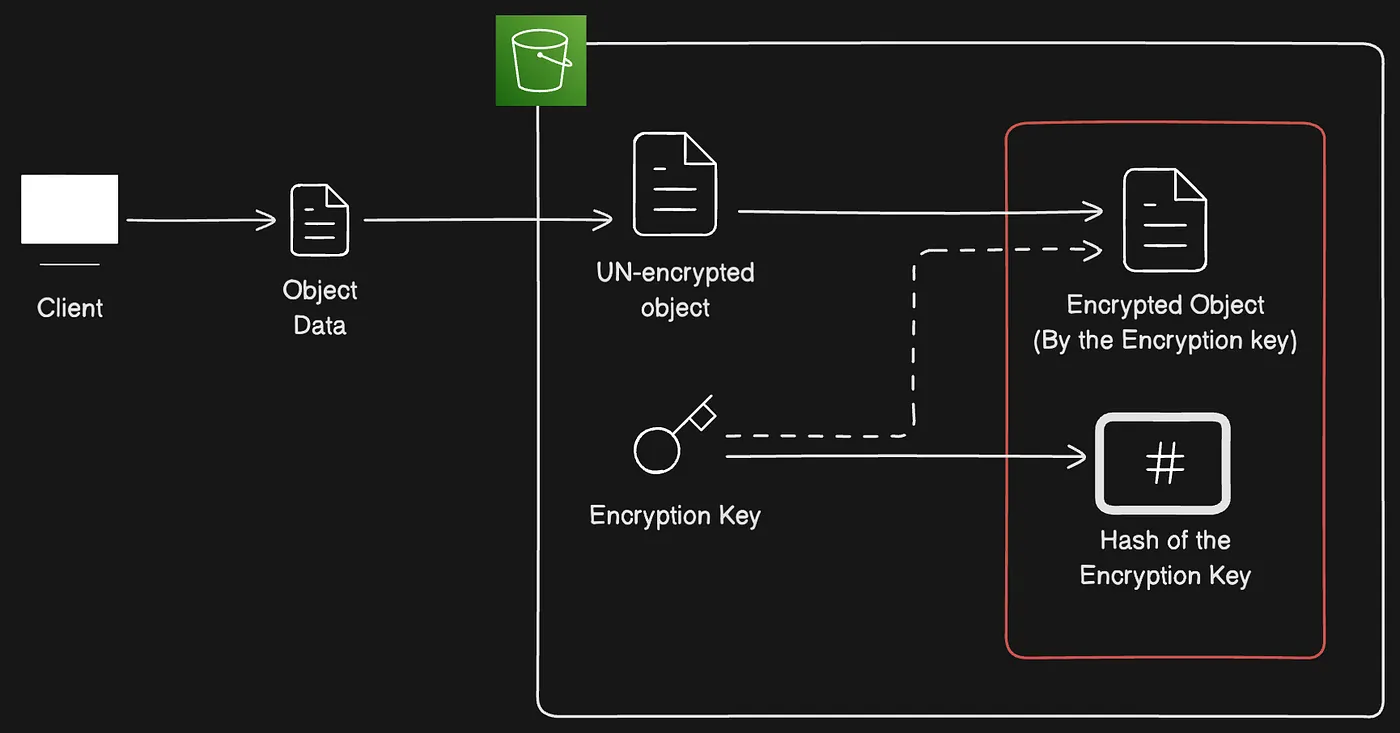 Luồng SSE-C dùng encryption key do client cung cấp để mã hóa object
Luồng SSE-C dùng encryption key do client cung cấp để mã hóa object
- Ứng dụng client cần cung cấp object chưa mã hóa và “encryption key” cho S3.
- S3 sau đó sử dụng “encryption key” để mã hóa object và loại bỏ “encryption key”.
- Trước khi bị loại bỏ, “encryption key” được hash và lưu cùng với encrypted object.
Client-Side Encryption
Client-side encryption là hành động mã hóa dữ liệu cục bộ để đảm bảo tính bảo mật khi truyền và khi lưu trữ. Để mã hóa object trước khi gửi đến Amazon S3, sử dụng Amazon S3 Encryption Client. Khi object được mã hóa theo cách này, object không bị lộ cho bất kỳ bên thứ ba nào, bao gồm cả AWS. Amazon S3 nhận object đã được mã hóa sẵn; Amazon S3 không đóng vai trò trong việc mã hóa hoặc giải mã object. Bạn có thể sử dụng cả Amazon S3 Encryption Client và server-side encryption để mã hóa dữ liệu. Khi gửi encrypted object đến Amazon S3, Amazon S3 không nhận ra object đã được mã hóa, nó chỉ phát hiện object bình thường.
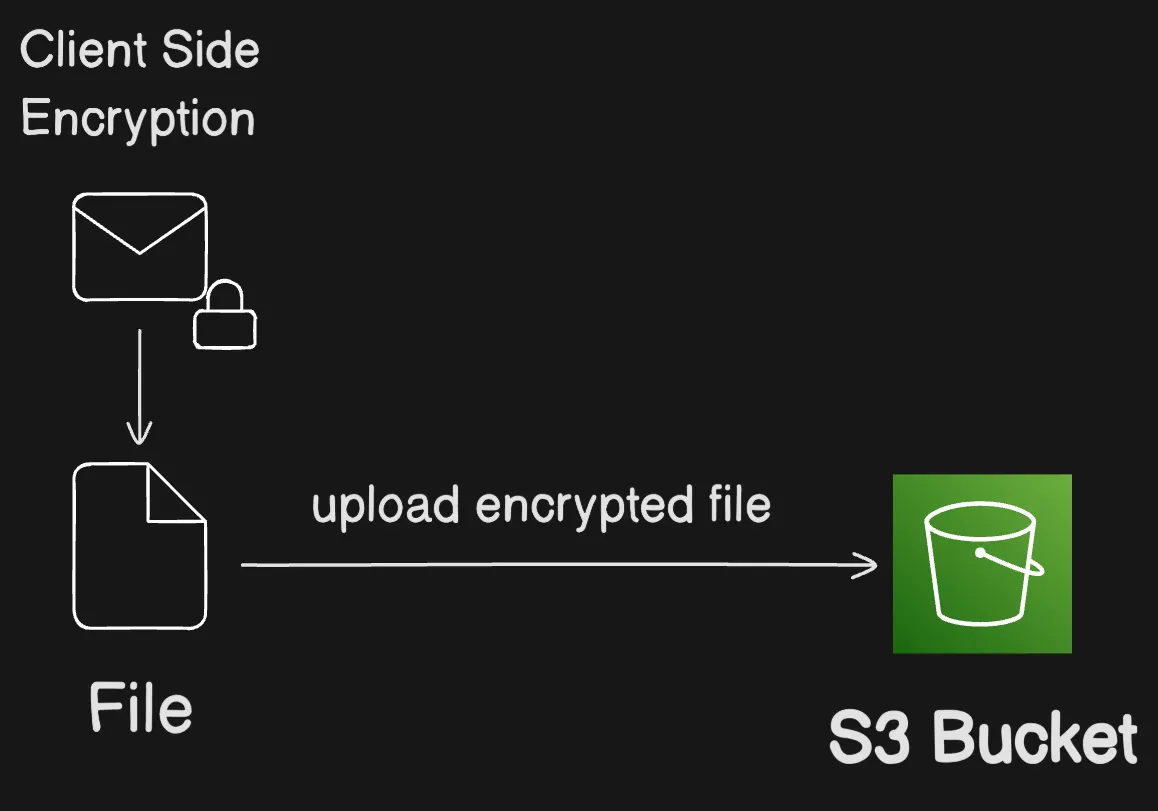 Client mã hóa dữ liệu cục bộ trước khi gửi object đã mã hóa lên S3
Client mã hóa dữ liệu cục bộ trước khi gửi object đã mã hóa lên S3
Amazon S3 Encryption Client hoạt động như trung gian giữa bạn và Amazon S3. Sau khi khởi tạo Amazon S3 Encryption Client, object tự động được mã hóa và giải mã như một phần của Amazon S3 PutObject và GetObject request. Tất cả object được mã hóa bằng data key duy nhất. Amazon S3 Encryption Client không sử dụng hoặc tương tác với bucket key, ngay cả khi bạn chỉ định KMS key làm wrapping key.
Data protection trong Amazon S3
Ngoài tính resilience (khả năng phục hồi) được cung cấp bởi AWS global infrastructure, Amazon S3 cung cấp nhiều tính năng giúp bảo vệ dữ liệu chống lại xóa nhầm hoặc lỗi Regional:
- S3 Replication: Bạn có thể sử dụng live replication để cho phép sao chép object tự động, bất đồng bộ qua các Amazon S3 bucket.
- Multi-Region Access Points và failover controls: Amazon S3 Multi-Region Access Points cung cấp global endpoint mà ứng dụng có thể sử dụng để thực hiện request từ S3 bucket ở nhiều AWS Region.
- S3 Versioning: Versioning là cách giữ nhiều biến thể (variant) của object trong cùng bucket. Bạn có thể sử dụng versioning để bảo tồn, truy xuất và khôi phục mọi phiên bản của mọi object lưu trong Amazon S3 bucket.
- S3 Object Lock: Bạn có thể sử dụng S3 Object Lock để lưu object sử dụng mô hình WORM. Sử dụng S3 Object Lock, bạn có thể ngăn object bị xóa hoặc ghi đè trong khoảng thời gian cố định hoặc vô thời hạn.
- AWS Backup: Amazon S3 được tích hợp nguyên bản với AWS Backup, dịch vụ fully managed dựa trên policy mà bạn có thể sử dụng để định nghĩa tập trung backup policy bảo vệ dữ liệu trong Amazon S3.
Sao chép object trong cùng Region và giữa các Region
Bạn có thể sử dụng replication để cho phép sao chép object tự động, bất đồng bộ qua các Amazon S3 bucket. Các bucket được cấu hình replication có thể thuộc cùng AWS account hoặc account khác nhau. Bạn có thể replicate object đến một bucket đích duy nhất hoặc nhiều bucket đích. Bucket đích có thể ở các AWS Region khác nhau hoặc cùng Region với bucket nguồn.
 Replication rule tự động sao chép object bất đồng bộ sang bucket đích
Replication rule tự động sao chép object bất đồng bộ sang bucket đích
Có hai loại replication: live replication và on-demand replication.
- Live replication — Để tự động replicate object mới và cập nhật khi chúng được ghi vào bucket nguồn, sử dụng live replication. Live replication không replicate object đã tồn tại trong bucket trước khi bạn thiết lập replication. Để replicate object đã tồn tại trước khi thiết lập replication, sử dụng on-demand replication.
- On-demand replication — Để replicate object hiện có từ bucket nguồn sang một hoặc nhiều bucket đích theo yêu cầu, sử dụng S3 Batch Replication.
Có hai hình thức live replication: Cross-Region Replication (CRR) và Same-Region Replication (SRR).
- Cross-Region Replication (CRR) — Bạn có thể sử dụng CRR để replicate object qua Amazon S3 bucket ở các AWS Region khác nhau.
- Same-Region Replication (SRR) — Bạn có thể sử dụng SRR để copy object qua Amazon S3 bucket trong cùng AWS Region.
Tại sao sử dụng replication?
Replication có thể giúp bạn:
- Replicate object giữ nguyên metadata — Bạn có thể sử dụng replication để tạo bản sao object giữ nguyên tất cả metadata, chẳng hạn thời gian tạo object gốc và version ID. Khả năng này quan trọng nếu bạn cần đảm bảo replica giống hệt source object.
- Replicate object sang storage class khác — Bạn có thể sử dụng replication để đặt trực tiếp object vào S3 Glacier Flexible Retrieval, S3 Glacier Deep Archive hoặc storage class khác trong bucket đích. Bạn cũng có thể replicate dữ liệu sang cùng storage class và sử dụng lifecycle configuration trên bucket đích để di chuyển object sang storage class lạnh hơn khi chúng cũ đi.
- Duy trì bản sao object dưới quyền sở hữu khác — Bất kể ai sở hữu source object, bạn có thể yêu cầu Amazon S3 đổi quyền sở hữu replica sang AWS account sở hữu bucket đích. Đây được gọi là tùy chọn owner override. Bạn có thể dùng tùy chọn này để giới hạn truy cập vào object replica.
- Lưu object trên nhiều AWS Region — Để đảm bảo sự khác biệt địa lý về nơi dữ liệu được lưu, bạn có thể thiết lập nhiều bucket đích ở các AWS Region khác nhau. Tính năng này có thể giúp đáp ứng các yêu cầu tuân thủ nhất định.
- Replicate object trong vòng 15 phút — Để replicate dữ liệu trong cùng AWS Region hoặc giữa các Region trong khung thời gian có thể dự đoán, bạn có thể sử dụng S3 Replication Time Control (S3 RTC). S3 RTC replicate 99,99% object mới lưu trong Amazon S3 trong vòng 15 phút (được đảm bảo bởi service-level agreement).
- Đồng bộ bucket, replicate object hiện có, và replicate object thất bại hoặc đã replicate trước đó — Để đồng bộ bucket và replicate object hiện có, sử dụng Batch Replication như hành động replication theo yêu cầu.
- Replicate object và failover sang bucket ở AWS Region khác — Để giữ tất cả metadata và object đồng bộ giữa các bucket trong quá trình replication, sử dụng two-way replication (hay bi-directional replication — sao chép hai chiều) rule trước khi cấu hình Amazon S3 Multi-Region Access Point failover controls. Two-way replication rule đảm bảo khi dữ liệu được ghi vào S3 bucket mà traffic failover đến, dữ liệu đó sau đó được replicate ngược lại bucket nguồn.
Khi nào sử dụng Cross-Region Replication
S3 Cross-Region Replication (CRR) được dùng để copy object qua Amazon S3 bucket ở các AWS Region khác nhau. CRR có thể giúp bạn:
- Đáp ứng yêu cầu tuân thủ — Mặc dù Amazon S3 mặc định lưu dữ liệu trên nhiều Availability Zone cách xa nhau về mặt địa lý, yêu cầu tuân thủ có thể quy định bạn phải lưu dữ liệu ở khoảng cách lớn hơn. Để đáp ứng yêu cầu này, sử dụng Cross-Region Replication để replicate dữ liệu giữa các AWS Region xa nhau.
- Giảm thiểu độ trễ — Nếu khách hàng ở hai vị trí địa lý, bạn có thể giảm thiểu độ trễ truy cập object bằng cách duy trì bản sao object tại AWS Region gần người dùng hơn.
- Tăng hiệu quả vận hành — Nếu bạn có compute cluster ở hai AWS Region khác nhau phân tích cùng tập object, bạn có thể chọn duy trì bản sao object tại các Region đó.
Khi nào sử dụng Same-Region Replication
Same-Region Replication (SRR) được dùng để copy object qua Amazon S3 bucket trong cùng AWS Region. SRR có thể giúp bạn:
- Tổng hợp log vào một bucket duy nhất — Nếu bạn lưu log trong nhiều bucket hoặc qua nhiều account, bạn có thể dễ dàng replicate log vào một bucket duy nhất trong cùng Region. Điều này cho phép xử lý log đơn giản hơn tại một vị trí.
- Cấu hình live replication giữa production và test account — Nếu bạn hoặc khách hàng có production và test account sử dụng cùng dữ liệu, bạn có thể replicate object giữa nhiều account, đồng thời giữ nguyên object metadata.
- Tuân thủ luật chủ quyền dữ liệu (data sovereignty) — Bạn có thể bị yêu cầu lưu nhiều bản sao dữ liệu trong các AWS account riêng biệt trong cùng Region. Same-Region Replication giúp tự động replicate dữ liệu quan trọng khi quy định tuân thủ không cho phép dữ liệu rời khỏi quốc gia.
Khi nào sử dụng two-way replication (bi-directional replication)
- Xây dựng shared dataset qua nhiều AWS Region — Với replica modification sync, bạn có thể dễ dàng replicate thay đổi metadata, chẳng hạn object access control list (ACL), object tag hoặc object lock, trên replication object. Two-way replication này quan trọng nếu bạn muốn giữ tất cả object và thay đổi object metadata đồng bộ. Bạn có thể bật replica modification sync trên replication rule mới hoặc hiện có khi thực hiện two-way replication giữa hai hoặc nhiều bucket trong cùng hoặc khác AWS Region.
- Giữ dữ liệu đồng bộ giữa các Region trong failover — Bạn có thể đồng bộ dữ liệu trong bucket giữa các AWS Region bằng cách cấu hình two-way replication rule với S3 Cross-Region Replication (CRR) trực tiếp từ Multi-Region Access Point. Để đưa ra quyết định sáng suốt về thời điểm khởi tạo failover, bạn cũng có thể bật S3 replication metrics để giám sát replication trong Amazon CloudWatch, trong S3 Replication Time Control (S3 RTC), hoặc từ Multi-Region Access Point.
- Làm ứng dụng có tính sẵn sàng cao — Ngay cả khi có gián đoạn traffic Regional, bạn có thể sử dụng two-way replication rule để giữ tất cả metadata và object đồng bộ giữa các bucket trong quá trình replication.
Khi nào sử dụng S3 Batch Replication
Batch Replication replicate object hiện có sang bucket khác như tùy chọn theo yêu cầu. Không giống live replication, các job này có thể chạy khi cần. Batch Replication có thể giúp bạn:
- Replicate object hiện có — Bạn có thể sử dụng Batch Replication để replicate object đã được thêm vào bucket trước khi Same-Region Replication hoặc Cross-Region Replication được cấu hình.
- Replicate object trước đó thất bại — Bạn có thể lọc Batch Replication job để thử replicate object có trạng thái replication là FAILED.
- Replicate object đã được replicate — Bạn có thể bị yêu cầu lưu nhiều bản sao dữ liệu trong các AWS account hoặc AWS Region riêng biệt. Batch Replication có thể replicate object hiện có sang destination mới thêm.
- Replicate replica của object được tạo từ replication rule — Replication configuration tạo replica của object trong bucket đích. Replica của object chỉ có thể được replicate bằng Batch Replication.
Multi-Region Access Points
Amazon S3 Multi-Region Access Points cung cấp global endpoint mà ứng dụng có thể sử dụng để thực hiện request từ S3 bucket ở nhiều AWS Region. Bạn có thể sử dụng Multi-Region Access Points để xây dựng ứng dụng multi-Region với cùng kiến trúc được dùng trong một Region, rồi chạy ứng dụng đó ở bất kỳ đâu trên thế giới. Thay vì gửi request qua internet công cộng tắc nghẽn, Multi-Region Access Points cung cấp network resilience tích hợp với tăng tốc cho các request dựa trên internet đến Amazon S3. Request ứng dụng gửi đến Multi-Region Access Point global endpoint sử dụng AWS Global Accelerator để tự động route qua AWS global network đến S3 bucket gần nhất có trạng thái routing active.
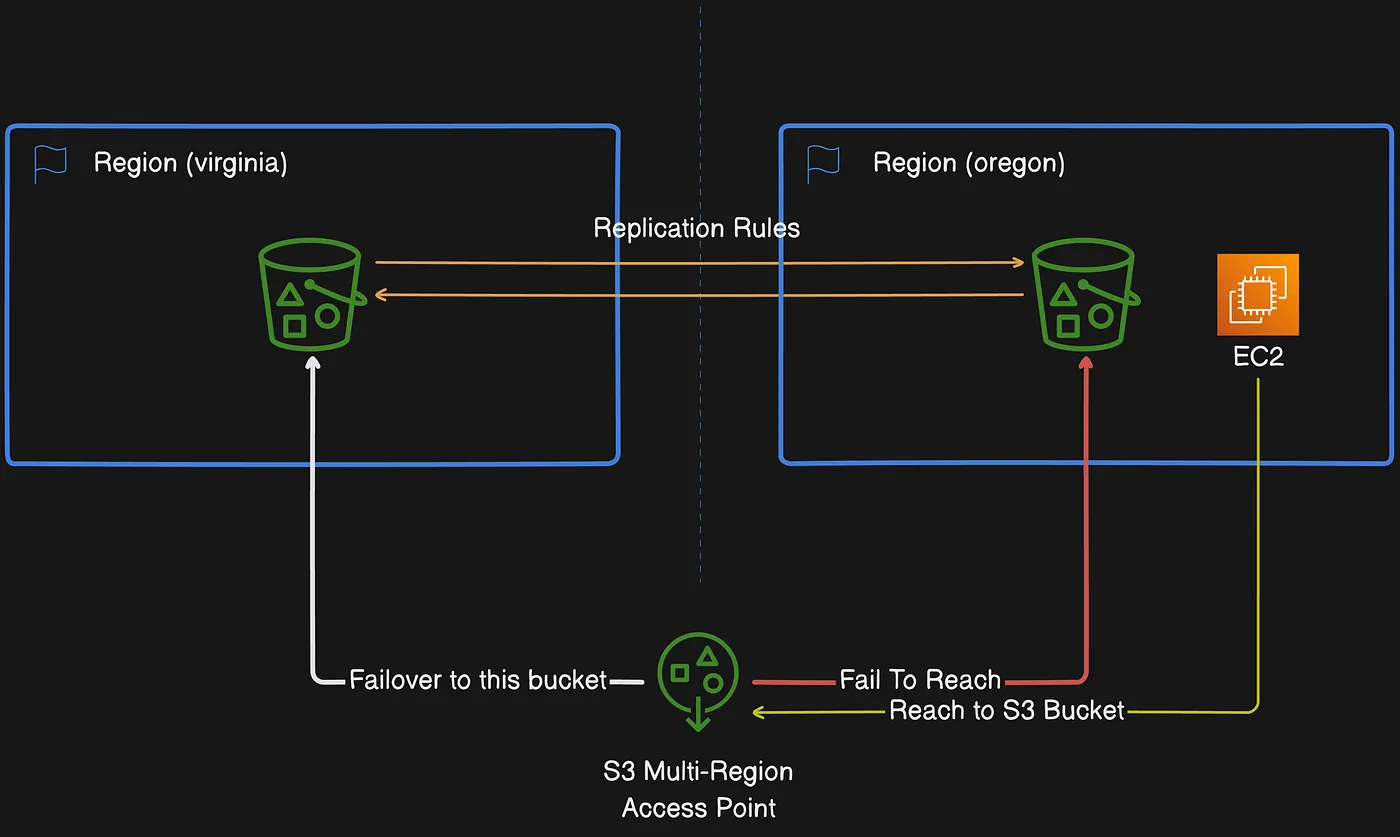 Multi-Region Access Point định tuyến request đến bucket gần nhất qua AWS global network
Multi-Region Access Point định tuyến request đến bucket gần nhất qua AWS global network
Nếu xảy ra gián đoạn traffic Regional, bạn có thể sử dụng Multi-Region Access Points failover controls để chuyển traffic request dữ liệu S3 giữa các AWS Region và chuyển hướng S3 traffic khỏi gián đoạn trong vài phút. Bạn cũng có thể kiểm tra khả năng phục hồi ứng dụng trước gián đoạn để thực hiện failover ứng dụng và mô phỏng disaster recovery. Nếu cần kết nối và tăng tốc request đến S3 từ bên ngoài VPC, bạn có thể đơn giản hóa kiến trúc ứng dụng và mạng với Amazon S3 Multi-Region Access Points. Request Multi-Region Access Points sẽ được route qua AWS global network rồi quay lại S3 trong AWS Region, không cần đi qua internet công cộng. Kết quả là bạn có thể xây dựng ứng dụng có tính sẵn sàng cao hơn.
Trong quá trình tạo và thiết lập Multi-Region Access Points, bạn sẽ chỉ định tập AWS Region nơi bạn muốn lưu dữ liệu được phục vụ qua Multi-Region Access Point đó. Bạn có thể sử dụng tên endpoint Multi-Region Access Points được cung cấp để kết nối client. Sau khi thiết lập kết nối client, bạn có thể chọn bucket hiện có hoặc mới mà bạn muốn route request Multi-Region Access Points giữa. Sau đó, sử dụng S3 Cross-Region Replication (CRR) rule để đồng bộ dữ liệu giữa bucket trong các Region đó.
Sau khi thiết lập Multi-Region Access Point, bạn có thể request hoặc ghi dữ liệu qua Multi-Region Access Points global endpoint. Amazon S3 tự động phục vụ request đến replicated data set từ Region gần nhất có sẵn.
S3 Versioning
Versioning trong Amazon S3 là cách giữ nhiều biến thể (variant) của object trong cùng bucket. Bạn có thể sử dụng tính năng S3 Versioning để bảo tồn, truy xuất và khôi phục mọi phiên bản của mọi object lưu trong bucket. Với versioning, bạn có thể phục hồi dễ dàng hơn từ cả hành động người dùng ngoài ý muốn và lỗi ứng dụng. Sau khi versioning được bật cho bucket, nếu Amazon S3 nhận nhiều write request cho cùng object đồng thời, nó lưu tất cả các object đó.
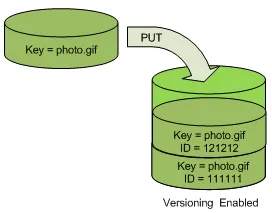 Một bucket chưa bật versioning chỉ giữ một phiên bản object
Một bucket chưa bật versioning chỉ giữ một phiên bản object Bucket bật versioning giữ nhiều phiên bản với version ID riêng
Bucket bật versioning giữ nhiều phiên bản với version ID riêng
Bucket có bật versioning giúp bạn khôi phục object từ xóa nhầm hoặc ghi đè. Ví dụ, nếu bạn xóa object, Amazon S3 chèn delete marker thay vì xóa vĩnh viễn object. Delete marker trở thành phiên bản object hiện tại. Nếu bạn ghi đè object, kết quả là phiên bản object mới trong bucket.
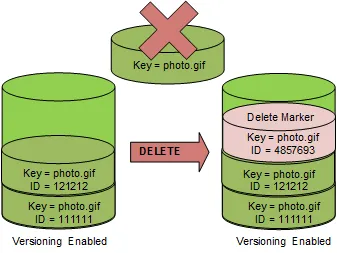 Xóa object chỉ chèn delete marker thay vì xóa vĩnh viễn
Xóa object chỉ chèn delete marker thay vì xóa vĩnh viễn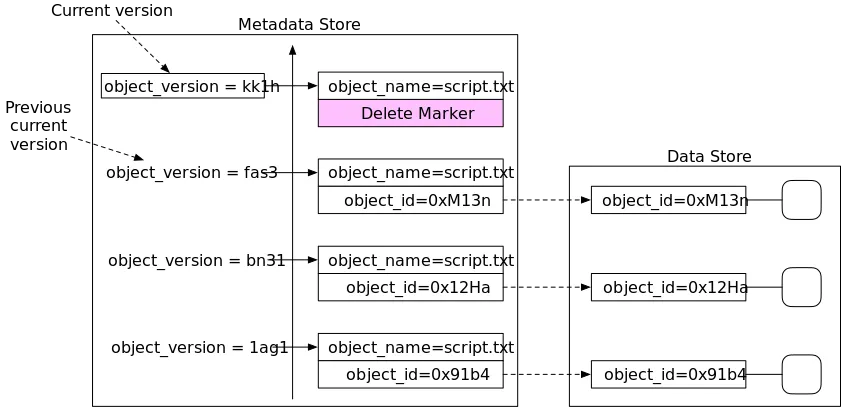 Ghi đè object tạo thêm phiên bản mới và giữ lại phiên bản cũ
Ghi đè object tạo thêm phiên bản mới và giữ lại phiên bản cũ
Mặc định, S3 Versioning bị tắt trên bucket, và bạn phải bật nó một cách rõ ràng.
Bucket có thể ở một trong ba trạng thái:
- Unversioned (mặc định)
- Versioning-enabled (đã bật versioning)
- Versioning-suspended (tạm dừng versioning)
Bạn bật và tạm dừng versioning ở cấp bucket. Sau khi bật versioning cho bucket, nó không bao giờ có thể quay lại trạng thái unversioned. Nhưng bạn có thể tạm dừng (suspend) versioning trên bucket đó.
Trạng thái versioning áp dụng cho tất cả (không bao giờ chỉ một số) object trong bucket. Khi bạn bật versioning trong bucket, tất cả object mới được versioned và được gán version ID duy nhất. Object đã tồn tại trong bucket tại thời điểm bật versioning sẽ luôn được versioned và gán version ID duy nhất khi chúng được sửa đổi bởi request trong tương lai. Lưu ý:
- Object được lưu trong bucket trước khi bạn thiết lập trạng thái versioning có version ID là
null. Khi bật versioning, object hiện có trong bucket không thay đổi. Điều thay đổi là cách Amazon S3 xử lý object trong các request tương lai. - Bucket owner (hoặc bất kỳ user nào có permission phù hợp) có thể tạm dừng versioning để ngừng tích lũy object version. Khi tạm dừng versioning, object hiện có trong bucket không thay đổi. Điều thay đổi là cách Amazon S3 xử lý object trong request tương lai.
Khóa object với Object Lock
S3 Object Lock giúp ngăn Amazon S3 object bị xóa hoặc ghi đè trong khoảng thời gian cố định hoặc vô thời hạn. Object Lock sử dụng mô hình write-once-read-many (WORM — ghi một lần đọc nhiều lần) để lưu object. Bạn có thể sử dụng Object Lock để đáp ứng yêu cầu pháp lý cần WORM storage, hoặc thêm lớp bảo vệ bổ sung chống thay đổi hoặc xóa object.
Object Lock cung cấp hai cách quản lý object retention: retention period (thời gian giữ lại) và legal hold (giữ lại theo pháp lý). Object version có thể có retention period, legal hold, hoặc cả hai.
- Retention period — Retention period chỉ định khoảng thời gian cố định mà object version bị khóa. Bạn có thể thiết lập retention period duy nhất cho từng object. Ngoài ra, bạn có thể thiết lập retention period mặc định trên S3 bucket. Bạn cũng có thể giới hạn retention period tối thiểu và tối đa cho phép bằng condition key
s3:object-lock-remaining-retention-daystrong bucket policy. Điều này giúp thiết lập phạm vi retention period và giới hạn retention period quá ngắn hoặc quá dài. - Legal hold — Legal hold cung cấp cùng bảo vệ như retention period, nhưng không có ngày hết hạn. Thay vào đó, legal hold duy trì cho đến khi bạn gỡ bỏ nó một cách rõ ràng. Legal hold độc lập với retention period và được áp dụng cho từng object version.
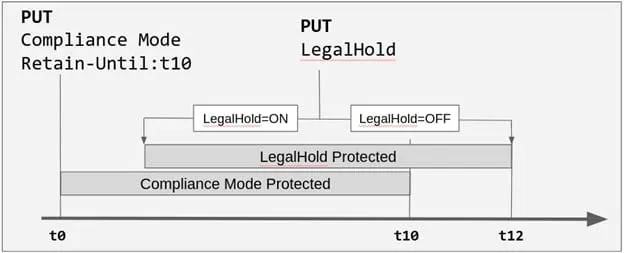 Object Lock dùng mô hình WORM với retention period và legal hold
Object Lock dùng mô hình WORM với retention period và legal hold
Object Lock chỉ hoạt động trong bucket có bật S3 Versioning. Khi khóa object version, Amazon S3 lưu thông tin khóa trong metadata của object version đó. Đặt retention period hoặc legal hold trên object chỉ bảo vệ version được chỉ định trong request. Retention period và legal hold không ngăn tạo version mới của object, hoặc thêm delete marker lên trên object.
Retention periods
Retention period bảo vệ object version trong khoảng thời gian cố định. Khi đặt retention period trên object version, Amazon S3 lưu timestamp trong metadata của object version để chỉ ra khi retention period hết hạn. Sau khi retention period hết hạn, object version có thể bị ghi đè hoặc xóa.
Bạn có thể đặt retention period rõ ràng trên từng object version hoặc trong thuộc tính bucket để nó tự động áp dụng cho tất cả object trong bucket. Khi áp dụng retention period cho object version một cách rõ ràng, bạn chỉ định Retain Until Date cho object version. Amazon S3 lưu ngày này trong metadata object version.
Bạn cũng có thể thiết lập retention period trong thuộc tính bucket. Khi thiết lập retention period trên bucket, bạn chỉ định duration, tính bằng ngày hoặc năm, cho thời gian bảo vệ mỗi object version đặt trong bucket. Khi bạn đặt object vào bucket, Amazon S3 tính Retain Until Date cho object version bằng cách cộng duration đã chỉ định vào timestamp tạo object version. Object version được bảo vệ chính xác như thể bạn đặt lock riêng lẻ với retention period đó trên object version.
Giống tất cả thiết lập Object Lock khác, retention period áp dụng cho từng object version. Các version khác nhau của cùng object có thể có retention mode và period khác nhau.
Ví dụ, giả sử bạn có object đang ở ngày thứ 15 của retention period 30 ngày, và bạn PUT object vào Amazon S3 với cùng tên và retention period 60 ngày. Trong trường hợp này, PUT request thành công, và Amazon S3 tạo version mới của object với retention period 60 ngày. Version cũ giữ nguyên retention period ban đầu và có thể xóa được sau 15 ngày.
Retention modes
S3 Object Lock cung cấp hai retention mode áp dụng các mức bảo vệ khác nhau cho object:
- Compliance mode
- Governance mode
Ở compliance mode, protected object version không thể bị ghi đè hoặc xóa bởi bất kỳ user nào, bao gồm root user trong AWS account. Khi object bị khóa ở compliance mode, retention mode không thể thay đổi, và retention period không thể rút ngắn. Compliance mode đảm bảo object version không thể bị ghi đè hoặc xóa trong suốt retention period.
Ở governance mode, user không thể ghi đè hoặc xóa object version hoặc thay đổi thiết lập lock trừ khi có permission đặc biệt. Với governance mode, bạn bảo vệ object khỏi bị xóa bởi hầu hết user, nhưng vẫn có thể cấp cho một số user permission để thay đổi retention setting hoặc xóa object nếu cần. Bạn cũng có thể sử dụng governance mode để kiểm tra thiết lập retention period trước khi tạo compliance-mode retention period.
Để override hoặc gỡ bỏ thiết lập governance-mode retention, bạn phải có permission s3:BypassGovernanceRetention và phải đính kèm x-amz-bypass-governance-retention:true một cách rõ ràng như request header với bất kỳ request nào yêu cầu override governance mode.
Legal holds
Với Object Lock, bạn cũng có thể đặt legal hold trên object version. Giống retention period, legal hold ngăn object version bị ghi đè hoặc xóa. Tuy nhiên, legal hold không có khoảng thời gian cố định và duy trì cho đến khi bị gỡ bỏ. Legal hold có thể được đặt và gỡ tự do bởi bất kỳ user nào có permission s3:PutObjectLegalHold.
Legal hold độc lập với retention period. Đặt legal hold trên object version không ảnh hưởng đến retention mode hoặc retention period của object version đó.
Ví dụ, giả sử bạn đặt legal hold trên object version và object version đó cũng được bảo vệ bởi retention period. Nếu retention period hết hạn, object không mất bảo vệ WORM. Thay vào đó, legal hold tiếp tục bảo vệ object cho đến khi user được ủy quyền gỡ bỏ legal hold một cách rõ ràng. Tương tự, nếu bạn gỡ legal hold trong khi object version có retention period đang hiệu lực, object version vẫn được bảo vệ cho đến khi retention period hết hạn.
Best practice cho S3 Object Lock
Cân nhắc sử dụng Governance mode nếu bạn muốn bảo vệ object khỏi bị xóa bởi hầu hết user trong retention period đã định, nhưng đồng thời muốn một số user có permission đặc biệt có thể linh hoạt thay đổi retention setting hoặc xóa object.
Cân nhắc sử dụng Compliance mode nếu bạn không bao giờ muốn bất kỳ user nào, bao gồm root user trong AWS account, có thể xóa object trong retention period đã định. Bạn có thể dùng mode này khi có yêu cầu lưu trữ dữ liệu tuân thủ.
Bạn có thể sử dụng Legal Hold khi không chắc chắn muốn object bất biến (immutable) trong bao lâu. Điều này có thể vì bạn có cuộc kiểm toán bên ngoài sắp tới và muốn giữ object bất biến cho đến khi kiểm toán hoàn tất. Hoặc bạn có dự án đang sử dụng dataset mà bạn muốn giữ bất biến cho đến khi dự án hoàn thành.
Backup dữ liệu Amazon S3
Amazon S3 được tích hợp nguyên bản với AWS Backup, dịch vụ fully managed dựa trên policy mà bạn có thể sử dụng để định nghĩa tập trung backup policy bảo vệ dữ liệu trong Amazon S3. Sau khi định nghĩa backup policy và gán tài nguyên Amazon S3 vào policy, AWS Backup tự động tạo Amazon S3 backup và lưu trữ an toàn backup trong encrypted backup vault mà bạn chỉ định trong backup plan.
Khi sử dụng AWS Backup cho Amazon S3, bạn có thể thực hiện các hành động sau:
- Tạo continuous backup và periodic backup. Continuous backup hữu ích cho point-in-time restore, và periodic backup hữu ích để đáp ứng nhu cầu lưu trữ dữ liệu dài hạn.
- Tự động hóa lịch backup và retention bằng cách cấu hình tập trung backup policy.
- Khôi phục backup dữ liệu Amazon S3 đến thời điểm bạn chỉ định.
Cùng với AWS Backup, bạn có thể sử dụng S3 Versioning và S3 Replication để phục hồi từ xóa nhầm và thực hiện các thao tác tự phục hồi.
Tối ưu hiệu suất Amazon S3
Ứng dụng của bạn có thể dễ dàng đạt hàng nghìn transaction mỗi giây về hiệu suất request khi upload và truy xuất lưu trữ từ Amazon S3. Amazon S3 tự động scale đến request rate cao. Ví dụ, ứng dụng có thể đạt ít nhất 3.500 PUT/COPY/POST/DELETE hoặc 5.500 GET/HEAD request mỗi giây cho mỗi Amazon S3 prefix được phân vùng (partitioned). Không có giới hạn số lượng prefix trong bucket. Bạn có thể tăng hiệu suất đọc hoặc ghi bằng parallelization (song song hóa). Ví dụ, nếu tạo 10 prefix trong Amazon S3 bucket để song song hóa đọc, bạn có thể scale hiệu suất đọc lên 55.000 read request mỗi giây. Tương tự, bạn có thể scale thao tác ghi bằng cách ghi vào nhiều prefix. Việc scaling, trong cả trường hợp đọc và ghi, diễn ra dần dần và không tức thời. Khi Amazon S3 đang scale đến request rate cao hơn mới, bạn có thể thấy một số lỗi 503 (Slow Down). Các lỗi này sẽ biến mất khi scaling hoàn tất.
 Mỗi prefix được phân vùng để scale request rate song song
Mỗi prefix được phân vùng để scale request rate song song
Một số ứng dụng data lake trên Amazon S3 quét hàng triệu hoặc hàng tỷ object cho các truy vấn chạy trên petabyte dữ liệu. Các ứng dụng data lake này đạt transfer rate đơn instance tối đa hóa sử dụng network interface cho Amazon EC2 instance, có thể lên tới 100 Gb/s trên một instance. Các ứng dụng này sau đó tổng hợp throughput qua nhiều instance để đạt nhiều terabit mỗi giây.
Các ứng dụng khác nhạy cảm về độ trễ, chẳng hạn ứng dụng social media messaging. Các ứng dụng này có thể đạt độ trễ small object nhất quán (và first-byte-out latency cho object lớn hơn) khoảng 100-200 mili giây.
Các dịch vụ AWS khác cũng có thể giúp tăng tốc hiệu suất cho các kiến trúc ứng dụng khác nhau. Ví dụ, nếu bạn muốn transfer rate cao hơn qua một HTTP connection đơn hoặc độ trễ mili giây đơn, sử dụng Amazon CloudFront hoặc Amazon ElastiCache để caching với Amazon S3.
Hướng dẫn hiệu suất cho Amazon S3
Scale storage connection theo chiều ngang
Phân tán request qua nhiều connection là design pattern phổ biến để scale hiệu suất theo chiều ngang. Khi xây dựng ứng dụng hiệu suất cao, hãy coi Amazon S3 là hệ thống phân tán rất lớn, không phải network endpoint đơn lẻ như storage server truyền thống. Bạn có thể đạt hiệu suất tốt nhất bằng cách gửi nhiều concurrent request đến Amazon S3. Phân tán các request này qua các connection riêng biệt để tối đa hóa bandwidth truy cập được từ Amazon S3. Amazon S3 không giới hạn số lượng connection đến bucket.
Sử dụng byte-range fetches
Sử dụng Range HTTP header trong GET Object request, bạn có thể fetch byte-range từ object, chỉ truyền phần được chỉ định. Bạn có thể sử dụng concurrent connection đến Amazon S3 để fetch các byte range khác nhau từ cùng object. Điều này giúp đạt aggregate throughput cao hơn so với request toàn bộ object đơn lẻ. Fetch range nhỏ hơn của object lớn cũng cho phép ứng dụng cải thiện thời gian retry khi request bị gián đoạn.
 Fetch song song nhiều byte-range từ cùng object để tăng throughput
Fetch song song nhiều byte-range từ cùng object để tăng throughput
Kích thước điển hình cho byte-range request là 8 MB hoặc 16 MB. Nếu object được PUT bằng multipart upload, best practice là GET chúng với cùng kích thước part (hoặc ít nhất aligned với ranh giới part) để có hiệu suất tốt nhất. GET request có thể trực tiếp truy cập từng part; ví dụ, GET ?partNumber=N.
Use case thứ hai mà S3 Byte-Range Fetches có thể được sử dụng là truy xuất chỉ dữ liệu một phần. Ví dụ, khi bạn biết XX byte đầu tiên là header của file, trong trường hợp này, nó có thể được sử dụng.
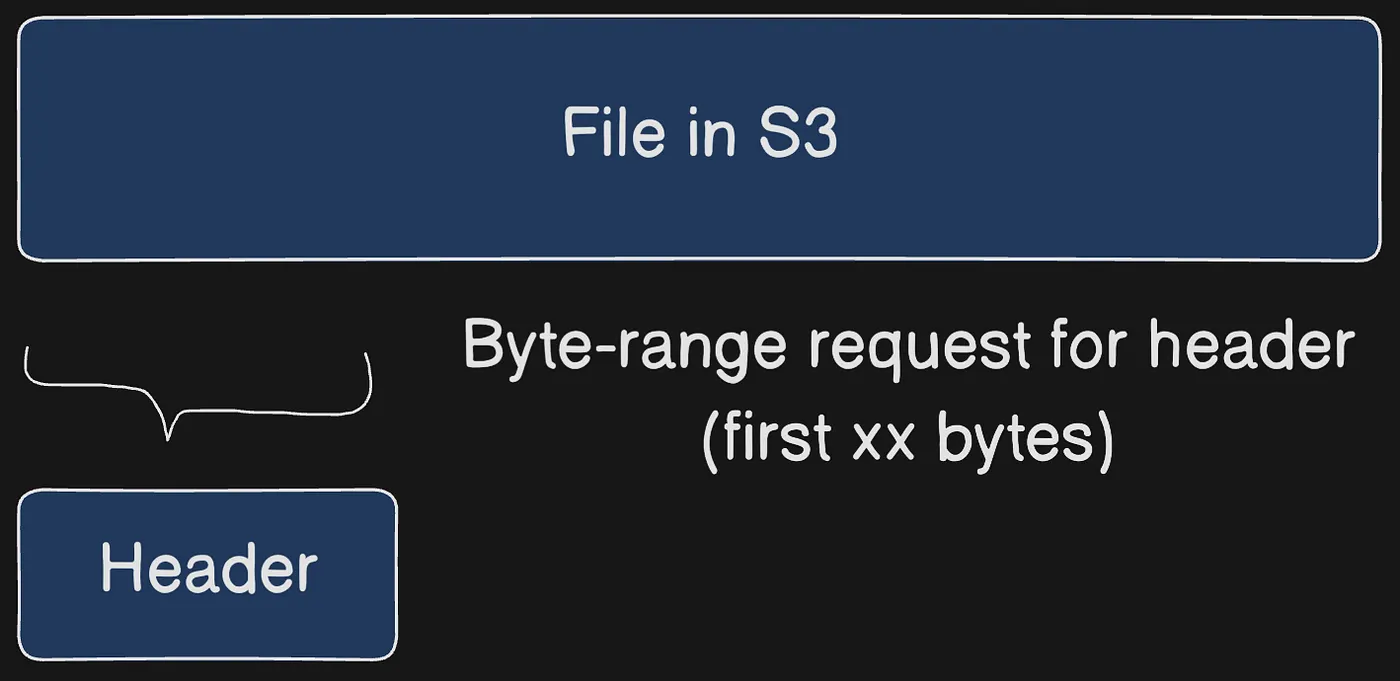 Byte-range request chỉ lấy phần header đầu file thay vì toàn bộ object
Byte-range request chỉ lấy phần header đầu file thay vì toàn bộ object
Retry request cho ứng dụng nhạy cảm về độ trễ
Aggressive timeout và retry giúp đạt độ trễ nhất quán. Với quy mô lớn của Amazon S3, nếu request đầu tiên chậm, request retry có khả năng đi theo đường khác và thành công nhanh chóng. AWS SDK có giá trị timeout và retry có thể cấu hình mà bạn có thể điều chỉnh theo tolerance của ứng dụng cụ thể.
Kết hợp Amazon S3 (Storage) và Amazon EC2 (Compute) trong cùng AWS Region
Mặc dù tên S3 bucket là globally unique, mỗi bucket được lưu trong Region bạn chọn khi tạo bucket. Để tối ưu hiệu suất, nên truy cập bucket từ Amazon EC2 instance trong cùng AWS Region khi có thể. Điều này giúp giảm network latency và chi phí data transfer.
Sử dụng Amazon S3 Transfer Acceleration để giảm thiểu độ trễ do khoảng cách
Cấu hình truyền file nhanh, an toàn bằng Amazon S3 Transfer Acceleration quản lý truyền file nhanh, dễ dàng và an toàn qua khoảng cách địa lý lớn giữa client và S3 bucket. Transfer Acceleration tận dụng các edge location phân bổ toàn cầu trong Amazon CloudFront . Khi dữ liệu đến edge location, nó được route đến Amazon S3 qua đường mạng được tối ưu. Transfer Acceleration lý tưởng cho việc truyền gigabyte đến terabyte dữ liệu thường xuyên qua các châu lục. Nó cũng hữu ích cho client upload đến bucket tập trung từ khắp nơi trên thế giới.
 Transfer Acceleration định tuyến dữ liệu qua edge location rồi về S3 qua đường tối ưu
Transfer Acceleration định tuyến dữ liệu qua edge location rồi về S3 qua đường tối ưu
Bạn có thể sử dụng Amazon S3 Transfer Acceleration Speed comparison tool để so sánh tốc độ upload có tăng tốc và không tăng tốc qua các Amazon S3 Region. Speed Comparison tool sử dụng multipart upload để truyền file từ trình duyệt đến các Amazon S3 Region có và không có Amazon S3 Transfer Acceleration.
 Mạng lưới edge location của CloudFront trải khắp toàn cầu
Mạng lưới edge location của CloudFront trải khắp toàn cầu
Sử dụng phiên bản AWS SDK mới nhất
AWS SDK cung cấp hỗ trợ tích hợp cho nhiều hướng dẫn được khuyến nghị nhằm tối ưu hiệu suất Amazon S3. SDK cung cấp API đơn giản hơn để tận dụng Amazon S3 từ bên trong ứng dụng và được cập nhật thường xuyên để tuân theo best practice mới nhất. Ví dụ, SDK bao gồm logic tự động retry request khi gặp lỗi HTTP 503 và đang đầu tư vào code để phản hồi và thích ứng với kết nối chậm.
Kết luận
AWS S3 là dịch vụ mở rộng và phức tạp. Mặc dù bài viết này đã cố gắng bao phủ các khía cạnh quan trọng nhất, chúng tôi khuyến khích bạn tìm hiểu thêm tài liệu chính thức để hiểu sâu hơn về các chủ đề cụ thể.
AWS S3 là nền tảng của lưu trữ đám mây hiện đại, cung cấp khả năng mở rộng, độ bền và tính linh hoạt vượt trội cho nhiều use case. Từ lưu trữ tài nguyên website tĩnh đến quản lý data lake lớn, S3 cung cấp các tính năng phục vụ developer, doanh nghiệp và enterprise. Sự tích hợp chặt chẽ với các dịch vụ AWS khác, như Lambda, Glue và Kinesis, cho phép workflow liền mạch và khả năng tự động hóa mạnh mẽ.